[ 수집한 공식/비공식 자료를 임의로 해석 후 정리하고 있는 게시글이기에 정확성이 다소 떨어질 수 있습니다. ]

[ Overview ]
Replication Graph는 4.20에 공개되고 4.21에 출시된, 언리얼 멀티플레이를 위한 대규모 최적화 기능이다.
Replication Graph의 필요성은 데디케이티드 서버의 한계에 달하는 100인을 목표로 출시된 게임들이 출시하고 흥행함에 따라 대두되었는데, 이것이 개발되기 전에는 각 게임 개발사에서 독자적으로 엔진을 수정하여 최적화하곤 했다.
이후 언리얼엔진 개발사인 에픽게임즈에서도 포트나이트 배틀로얄이 흥행함에 따라 공식적인 대규모 최적화 방식을 개발하고 적용한 뒤에 Replication Graph를 공개했다.
이름과 달리 C++로만 공식적으로 지원되며, 언급했듯이 포트나이트에서 사용함으로써 라이브 성능이 검증되었다.
[ Basic Explanation from Dennis Andersson's ReplicationGraph Tutorial ]
[ Optimization Concepts ]
1) Grid Spatialization : Sort actors in to groups based on location
사전에 정의된 특정 장소들(Grid)은 특정한 Connection에게 update를 전혀 보내지않음으로써 Performance 향상
1-A) Throttle network updates :Static, Dynamic or Dormant actor routes
Actor가 무엇을 하는지에 따라 Update Frequency를 설정하는 것은 Bandwidth를 감소시킬 수 있음.
1-B) DependentActorList : Update actors when their owner updates
Character가 Weapon을 소유하고 있을 때, Character가 업데이트되면 Weapon을 업데이트해서 Weapon Actor를 따로 처리할 필요가 없도록 함.
2) AlwaysRelevant Node : list of actors that are always knows to all connections
모든 Connection이 항상 알고있는(Relevant) Actor들의 목록
3) AlwaysRelevant ForConnection Node : List of actors that a certain connection always knows about
특정 Connection이 항상 알고있는(Relevant) Actor들의 목록
[ The ReplicationGraph Nodes ]
기본적으로 지원되는 Nodes.
1) Grid Spatialization Node (UReplicationGraphNode_GridSpatialization2D)
World를 Grid Cells로 쪼개는 개념.
Connection은 어떤 한 Actor가 속해있는 cell에 따라 Net Update 수신 여부를 결정.
Actor Replication을 다양한 방식(Static, Dynamic and Dormant)으로 처리.
2) Always Relevant Node (UReplicationGraphNode_AlwaysRelevant)
모든 Connection에 대해 Net Update를 항상 보내야하는 Actor들을 처리.
3) Always Relevant For Connection Node (UReplicationGraphNode_AlwaysRelevant_ForConnection)
특정한 Connection에 대해 Net Update를 항상 보내야하는 Actor들을 처리.
[ Engine Code Comments in ReplicationGraph.h ]
ReplicationGraph
Implementation of Replication Driver. This is customizable via subclassing UReplicationGraph. Default implementation (UReplicationGraph) does not fully function and is intended to be overridden.
Check out BasicReplicationGraph.h for a minimal implementation that works "out of the box" with a minimal feature set.
Check out ShooterGame / UShooterReplicationGraph for a more advanced implementation.
High level overview of ReplicationGraph:
The graph is a collection of nodes which produce "replication lists" for each network connection. The graph essentially maintains persistent lists of actors to replicate and feeds them to connections.
This allows for more work to be shared and greatly improves the scalability of the system with respect to number of actors * number of connections.
For example, one node on the graph is the spatialization node. All actors that essentially use distance based relevancy will go here. There are also always relevant nodes. Nodes can be global, per connection, or shared (E.g, "Always relevant for team" nodes).
The main impact here is that virtual functions like IsNetRelevantFor and GetNetPriority are not used by the replication graph. Several properties are also not used or are slightly different in use.
ReplicationDriver의 구현. UReplicationGraph를 서브클래싱하여 커스터마이징할 수 있습니다. 기본 구현(UReplicationGraph)은 완전히 작동하지 않으며 오버라이드되도록 의도되었습니다. 최소한의 기능 세트로 "즉시 사용 가능한" 최소한의 구현은 BasicReplicationGraph.h에서 확인하세요. 보다 고급 구현은 ShooterGame/UShooterReplicationGraph에서 확인하세요.
그래프는 각 네트워크 연결에 대한 복제 목록을 생성하는 노드 모음입니다. 그래프는 본질적으로 복제할 액터의 지속되는 목록을 유지 관리하고 연결에 공급합니다.
이를 통해 더 많은 작업을 공유할 수 있고 (액터 수 * 연결 수)와 관련하여 시스템의 확장성이 크게 향상됩니다.
예를 들어 그래프의 한 노드는 Spatialization 노드입니다. 거리 기반 관련성을 본질적으로 사용하는 모든 액터가 여기에 있습니다. AlwaysRelevant 노드도 있습니다. 노드는 Global, PerConnection 또는 Shared(예: "팀에 항상 관련됨" 노드)일 수 있습니다.
여기서 가장 큰 영향은 IsNetRelevantFor() 및 GetNetPriority()와 같은 가상 함수가 복제 그래프에서 사용되지 않는다는 것입니다. 여러 프로퍼티들도 사용되지 않거나 사용 방식이 약간 다릅니다.
Instead there are essentially three ways for game code to affect this part of replication:
The graph itself : Adding new UReplicationNodes or changing the way an actor is placed in the graph.
FGlobalActorReplicationInfo: The associative data the replication graph keeps, globally, about each actor.
FConnectionReplicationActorInfo: The associative data that the replication keeps, per connection, about each actor.
대신 게임 코드가 복제의 이 부분에 영향을 미치는 방법은 기본적으로 세 가지가 있습니다.
최상단에 있는 그래프 본체 : 새 UReplicationNodes를 추가하거나 액터가 그래프에 배치되는 방식을 변경합니다.
FGlobalActorReplicationInfo: 복제 그래프가 각 액터에 대해 전역적으로 보관하는 연관 데이터입니다. FConnectionReplicationActorInfo: 복제가 연결당 각 액터에 대해 보관하는 연관 데이터입니다.
After returned from the graph, the actor lists are further culled for distance and frequency, then merged and prioritized. The end result is a sorted list of actors to replicate that we then do logic for creating or updating actor channels.
그래프에서 반환된 후 액터 목록은 Distance와 Frequency에 대해 추가로 Culling된 다음 병합되고 Prioritized됩니다. 최종 결과는 복제할 액터의 정렬된 목록이며, 그런 다음 액터 채널을 만들거나 업데이트하기 위한 로직을 수행합니다.
[ Unreal Engine Official LiveStream Note : Networking in 4.20: The Replication Graph ]
https://www.youtube.com/live/CDnNAAzgltw
답변자 : Dave Ratti (Technical Lead), Ryan(Network Lead)
(09:00~)
Replication Graph, let me first start and say this a bit of a warning this is kind of more advanced stuff. and if you're new to networking and replication the stuff that Ryan is going to go through is going to be a lot kind of better for you to start with. This also doesn't if you're learning networking, learning replicated properties and RPCs and how to write game systems in networking, that's kind of like the first thing you should be focusing on. This really is about server performance and especially with games with lots of players like 100 players and lots and high actors Fortnite Battle Royale has 40'000~50'000 replicated actors in that map. so that's kind of the scale that we're at end. this is kind of like more advanced stuff. so just kind of keep that in mind as I go through.
리플리케이션 그래프를 시작하기에 앞서, 먼저 경고를 드리고 시작하겠습니다. 이것은 좀 더 고급적인 내용입니다. 네트워킹과 복제를 처음 접한다면 Ryan이 다룰 내용이 시작하기에 훨씬 나을 것입니다. 또한 여러분이 네트워킹을 배우고, 복제된 프로퍼티와 RPC를 배우고, 네트워킹에서 게임 시스템을 작성하는 방법을 배우고 있는 경우에도 마찬가지입니다. 그런 것들이 가장 먼저 집중해야 할 사항입니다. 이것은 실제로 서버 성능에 관한 것이며 특히 Fortnite Battle Royale처럼 맵에 100명의 플레이어와 4~5만개의 복제된 액터가 있는 게임에 관한 것입니다. 그래서 이것이 우리가 도달한 규모입니다. 이것은 좀 더 고급적인 내용입니다. 따라서 제가 설명할 때 이 점을 명심하세요.
Replication Graph is a implementation of Replication Driver.
ReplicationDriver is a new thing in 4.20 which allows you to customize the replication logic within the network driver.
The network drivers already subclass based on sort of a socket level, stuff like IpNetDriver and various platforms will subclass that differently so that's why we kind of have to go like a different vector there on in terms of customization.
so ReplicationDriver is a new thing and you can customize your replication logic with it. and so what does that actually mean it mainly means customizing ServerReplicateActors(), this is kind of a sort of longtime existing function that basically determines what actors should replicate to what connections.
what does that actually means opening ActorChannels calling replicate actor on those ActorChannels and then figuring out when to close those ActorChannels. that's really all this stuff is doing is finding the most efficient way to give in 50,000 actors and 100 Connections how to figure out which of those combinations should to do those kind of three operations. so that's kind of the part of the pipeline that we're really talking about.
once you decide to replicate an actor and you do property replication and that's where you Delta the property if we figure out what's changed, we serialize and we eventually write two packets and compress and do all these other things that kind of happens at the end and that's not kind of what we're talking about right here.
this is kind of this limited this kind of upfront phase of the pipeline that's kind of previously been hard to do these types of optimizations with and so let me explain what i mean by that so you know usually in Unreal what you normally have is you have like these virtual functions on your actors you have like IsRelevantFor and like GetNetPriority and you have a bunch of like variables on the actor itself that you can change and that will determine like who replicates to and how often they replicate and that's a good model it's kind of your classic like Object Oriented Programming model, and that's like easy to understand and it's easy to work with but it's very hard if not impossible to do these kind of like high-level optimizations.
for kind of what you need to do for a game like BR and so and what i mean by that is when very actor just has a virtual function that you have to call and it's going to do whatever it wants to do like you have no idea what actor is going to what they're going to do frame to frame, you can't have to kind of call that those functions all the time. because you can't rely on like when is the output gonna change of it, when is the return value is going to change, you don't know what that objects doing. it's just a black box right?
so it's really hard to like to make these kind of optimizations and basically the old system becomes slow when it's sort of when you scale on those two axes on connection count an actor count, you just have to you're continually calling those functions and continually kind of like redoing work because you have no insight.
so ReplicationGraph is kind of like the answer all that by creating a more persistent data structure for connections and actors such that you can quickly pull the data you want out of that and kind of get it on to the next phase of the pipeline.
ReplicationGraph는 Replication Driver의 구현입니다.
Replication Driver는 4.20 에서 새롭게 추가된 기능으로, Network Driver 내에서 복제 로직을 커스터마이징할 수 있습니다.
Network Driver는 이미 일련의 소켓 단계에서 서브 클래스화 되어 있으며, IpNetDriver와 같은 것과 다양한 플랫폼에서 이를 다르게 서브 클래스화할 것이므로 커스터마이징 측면에서 다른 벡터(방향성)를 가져야 합니다.
Replication Driver는 새로운 기능이며 이를 사용하여 복제 로직을 커스터마이징할 수 있습니다. 그리고 실제로 이것이 의미하는 바는 주로 ServerReplicateActors()를 커스터마이징하는 것을 의미합니다. 이것은 기본적으로 어떤 액터가 어떤 커넥션에 복제해야 하는지 결정하는 일종의 오래된 기존 함수입니다.
실제로 이것이 의미하는 바는 액터 채널을 열고 해당 액터 채널에서 복제될 액터를 호출한 다음 해당 액터 채널을 닫을 시기를 파악하는 것입니다. 이것이 실제로 하는 모든 작업의 전부이며 50,000개의 액터와 100개의 연결에 가장 효율적인 방법을 제공하여 이러한 세 가지 작업을 수행해야 하는 조합을 파악하는 방법입니다. 그래서 그게 우리가 실제로 이야기하는 파이프라인의 일부입니다.
액터를 복제하기로 결정하고 Property Replication을 수행하면 Property를 델타화합니다. 무엇이 변경되었는지 알아내고 직렬화하고 결국 두 개의 패킷을 작성하고 압축하고 마지막에 발생하는 모든 다른 작업을 수행하지만 지금 이야기할려고 하는 것은 그런게 아닙니다. 지금 다루고 있는 주제는 파이프라인의 이런 종류의 제한된 사전 단계인데, 이전에는 이런 종류의 최적화를 하는 것이 어려웠습니다. 제가 무슨 말인지 설명해 드리겠습니다. 아시다시피 언리얼에서 일반적으로 하는 일은 액터에 IsRelevantFor, GetNetPriority같은 가상 함수가 있고, 액터 자체에 변경할 수 있는 변수가 많이 있어서 누가 복제하고 얼마나 자주 복제할지를 결정합니다. 좋은 모델입니다. 고전적인 객체 지향 프로그래밍 모델과 같고, 이해하기 쉽고 작업하기 쉽지만 이런 종류의 고수준 최적화를 하는 것은 매우 어렵거나 불가능합니다. 배틀로얄 장르 게임에서 해야 할 일에 대해서, 그리고 제가 말하려는 것은 모든 액터가 호출해야 하는 가상 함수가 있고 그것이 원하는 것을 할 때입니다. 어떤 액터가 프레임마다 무엇을 할지 전혀 알 수 없고, 항상 그 함수를 호출할 필요가 없습니다. 함수의 아웃풋이 언제 변경될지, 즉 리턴 값이 언제 변경될지 신뢰할 수 없고, 그 객체가 무엇을 하는지 알 수 없기 때문입니다. (내부를 잘 모르겠으니) 그냥 블랙박스일 뿐이죠?
그래서 이런 종류의 최적화를 하는 것이 정말 어렵고, 기본적으로 이전 시스템은 연결 수(X)와 액터 수(Y)의 두 축에서 확장할 때(X * Y) 느려집니다. 그저 그 함수를 계속 호출하고 내부를 알아볼 수 없기 때문에 작업을 계속 다시 해야 합니다.
따라서 ReplicationGraph는 연결과 액터에 대한 보다 영속적인 데이터 구조(Persistent Data Structure)를 생성하여 원하는 데이터를 빠르게 꺼내 파이프라인의 다음 단계로 넘길 수 있도록 하여 이 모든 것에 대한 답과 같습니다.
/* 부가설명
전통적인 Replication에서 최적화는 IsNetRelevantFor(), GetNetPriority()를 override해서 Relevancy에 관해 액터마다 커스터마이징을 함으로써 이루어졌다. 하지만, 이는 매 프레임 고유한 액터별로 중복된 작업을 진행하는 것이었고, 구조적으로 문제가 있었다는 것이다. 이걸 Polling system이라고 하고, Replication Driver를 이용한 Replication Graph는 Push system에 해당하는 것이다.
가령 어떤 액터가 Relevant하다고 가정해보자. 다음 프레임에도 Relevant한가? 아마도 그럴 것이다. 액터가 엄청나게 빠르게 이동하는 것이 아닌 이상, 이전 프레임에서 Relevant했다면 이번 프레임에서도 Relevant할 확률이 높다. 하지만 virtual function이기 때문에 어떠한 경우의 수도 return이 가능하기에, 매번 중복되는 Relevancy 판정을 해야한다는 것이다.
그렇기 때문에 매 프레임 복제 하기 전, Relevancy를 결정하는 단계에서 이뤄지는 작업들 중 중복을 줄이기 위해 Graph 형태를 사용하는 것인데, 어떤 Node에서 매 프레임 단 한 번만 계산되어도 상관없는 작업은 Persistent Data Structure에 저장한 뒤, 전역으로 보관하거나 Node가 아닌 상위 그래프 본체에 저장함으로써 Redundancy를 최소화 하는 것이다. 이에 대한 가장 간단한 예시가 FGlobalActorReplicationInfo 에 있는 WorldLocation 같은 것인데, 이후에 다시 등장한다.
-> ReplicationGraph는 OOP를 적극 활용하는 Legacy System으로 부터 부분적으로 벗어나 Data-Oriented Design을 적용한 모델이라고 볼 수 있다.
========================
Polling System :
실제로 NetDriver의 ServerReplicatActors()의 코드를 보면, 처음에 잠재적인 복제대상들을 찾아 ConsiderList라는 것에 담은 뒤, 모든 Connection들에 대해 for loop를 돌면서, 또 모든 ConsiderList에 대해 for loop를 돌며 IsNetRelevantFor()를 통해 복제 대상을 수집한다. 그러니까 복제될 리스트만 뽑아내서 Push하는 것이 아니라 모든 잠재적인 복제대상에 대해 일일이 찾아가면서 확인해보는 것.
========================
*/
[ Fortnite Replication Graph ]
Let me just give an example. I'm gonna just bring up what the Fortnite Replication Graph looks like.
I'm not gonna actually explain what the nodes do yet. we're gonna kind of work up to that.
but just kind of as an example. this is something that kind of as we were making this I thought kind of try to help explain it but the idea here being kind of the high-level you have like sort of the ReplicationGraph is kind of like the Root Node and then it has like nodes within this graph and these nodes in this graph.
예를 하나 들어보겠습니다. Fortnite 리플리케이션 그래프가 어떤 모습인지 말씀드리겠습니다. 노드가 무엇을 하는지는 아직 설명하지 않겠습니다. 우리는 그것을 다루어 볼 것입니다. 하지만 그냥 예를 들어보겠습니다. 이건 우리가 이걸 만들 때 설명을 돕고 싶었던 것인데, 여기서 아이디어는 리플리케이션 그래프가 루트 노드와 같은 상위 레벨이고, 이 그래프 안에 노드가 있고, 이 그래프 안에 노드가 있다는 것입니다.
Their(nodes) job is ultimately to produce actor lists to replicate for a given connection.
so we say "hey replication graph, here is this connection. give me actors that should replicate to it and the replication graph will return a lists of actor lists.
노드가 궁극적으로 하는 일은 주어진 연결에 대해 리플리케이트할 Actor Lists를 생성하는 것입니다.
따라서 “hey ReplicationGraph, 여기 Connection이 있어. 이 Connection에 대해 replicate해야 할 액터들을 주면 리플리케이션 그래프가 Actorlists들을 반환해줄게.”라고 말하는 겁니다.
- Grid Spatialization 2D
이 node의 가장 큰 특징은 맵을 Grid 단위로 조각(carve)내서 복제 여부를 결정한다는 것입니다.
- Player States
Player State. Game State 같은 manager는 spatialized 되지 않습니다.
포트나이트에는 이외에도 편리한 몇몇의 manager actor가 있는데, 실제로 spatialized 되지 않습니다.
이런 Actor들은 때때로 모두에게 relevant 하거나 특정한 사람(Team)에게만 relevent합니다.
예시로 PlayerController의 경우 Connection에게만 relevant합니다.
실제로 spatialize하지 않는 것들까지 전부 spatialize하려고 하는 것은 이치에 맞지 않으므로
이런 유형의 클래스를 처리하기 위해 다른 노드가 있어야 합니다. 다른 노드를 추가함으로써 다양한 case를 처리해야 합니다.
[ 17:00 ~ 18:00 ]
There's a couple other advantages to doing this (if) you have this type of apporach. so mainly a lot of the work is able to be shared across Connections and across frames like once you have this like these persistent data structures, you're able to (you know) clients generally don't move very far very fast so like after in subsequent frames we end up not having to sort of do so much work. everything's kind of like.... I'll explain that part a little bit later as we dive right in I think what might make sense the most sense is to go into like maybe go into some of the code and kind of step through that and maybe explain just a little bit of how this stuff is knid of setup.
이러한 유형의 접근 방식을 사용하면 몇 가지 다른 이점이 있습니다. 주로 많은 작업을 Connections와 Frames간에 공유 할 수 있습니다. 이러한 영속적인 데이터 구조가 있으면 클라이언트가 일반적으로 매우 빠르게 이동하지 않으므로 후속 프레임에서 많은 작업을 수행 할 필요가 없습니다. 이 부분은 나중에 바로 들어가서 설명할 테니 코드 일부를 살펴보고 이 부분이 어떻게 설정되는지 조금만 설명하는 것이 가장 합리적일 것 같습니다.
ReplicationGraph.h is kind of like probably the best place to start. there is a decent amount of comments that kind of explain like what the subclasses are intended to implement.
ReplicationGraph.h는 아마도 시작하기에 가장 좋은 곳일 겁니다. 서브클래스가 구현하려는 내용을 설명하는 상당한 양의 주석이 있습니다.
[ BasicReplicationGraph ]
A basic implementation of replication graph. It only supports NetCullDistanceSquared, bAlwaysRelevant, bOnlyRelevantToOwner. These values cannot change per-actor at runtime.
This is meant to provide a simple example implementation. More robust implementations will be required for more complex games. ShooterGame is another example to check out.
엔진 코드에 기본적으로 포함되어 있는 최소 기능만을 사용한 예제.
아래 세 가지 조건만 적용됨. 이러한 값들은 런타임에 액터별로 변경할 수 없습니다.
이는 간단한 구현 예제를 제공하기 위한 것입니다. 더 복잡한 게임에는 더 강력한 구현이 필요합니다. ShooterGame은 살펴볼 수 있는 또 다른 예시입니다.
1) NetCullDistanceSquared
2) bAlwaysRelevant
3) bOnlyRelevantToOwner
[ 주요 struct... 등등 설명 ]
[ FClassReplicationInfo ]

just as an example, so this keeps a little data structure for that's associated with your class and normally this would kind of be like in kind of the old system, this would be data that would just be on the actor itself and without getting too far into the merits of object-oriented programming versus data-oriented programming that's not always the best, that's not always what you want like this data is really doesn't change for instance of the actual actor, it's something that just is a property of the class itself and so it does a lot of like things based on just what the actor is and not on properties that are actually on the actors off. so my main point being is you have FClassReplicationInfo that will determine certain things about the actors.
예시로 들자면, 이건 클래스와 관련된 작은 데이터 구조를 유지하는데, 보통은 이전 시스템이랑 동일한건데요. 이 데이터는 액터 자체에 있는 데이터입니다. 하지만 객체 지향 프로그래밍과 데이터 지향 프로그래밍의 장단점에 대해 너무 깊이 들어가지는 않겠지만, 이게 항상 가장 좋은 건 아니고, 항상 원하는 바도 아닙니다. 이 데이터는 실제 액터의 경우 실제로 변경되지 않습니다. 이 데이터는 클래스 자체의 프로퍼티일 뿐이므로 액터의 프로퍼티가 아니라 액터가 무엇인지에 따라 많은 작업을 수행합니다. 제가 말하고 싶은 것은 액터에 대한 특정한 사항을 결정하는 FClassReplicationInfo가 있다는 것입니다.

[ FGlobalActorReplicationInfo ]
이 struct에 있는 정보는 매우 빠르게 접근할 수 있어야 하기 때문에 전역으로 캐싱된 정보들이 있는 것이고, 변수들의 배치가 cache-conscious 하게 되어 있음. 접근 빈도를 고려하여 높은 확률로 캐시 메모리내에 존재할 수 있게 배치한 것.
그래서 struct내에서 상단에 있을수록 struct내에서도 크기가 작고 자주 접근하는 데이터이고, 반대로 아래로 갈수록 크기가 커서 접근을 최소화해야 하는 데이터이다.
ex) FGlobalActorReplicationEvents Events


: 특정 NetConnection에 대한게 아니라, 모든 NetConnection에 대해 적용되는 것.

Dave : 이전 시스템(Legacy ServerReplicateActors())보다 현 시스템이 더 빠른 이유는 무엇인가요? 이건 또 다른 설명 흐름으로 넘어가게 됩니다만, GetActorLocation() 함수와 관련된 것인데요. ServerReplicateActors() 상단부, 그리고 GetActorLocation() 함수 내부에 Break Point를 걸어놓고 게임을 진행해보면 해당 함수가 미친듯이 호출되는걸 볼 수 있습니다.
해당 Actor의 Location을 빠르게 받아오는 것 같지만 매번 RootComponent를 찾아야하고, Transform을 리턴해야 하기에 이 모든것들은 엄청난 중복인겁니다. 실제로 단일 프레임내에서 위치가 변경되지 않는데도요.
그래서 여기에 WorldLocation으로 캐싱하고, FVector는 크기가 작은 구조체이기 때문에 바라건대 하나의 Cache line안에 위치해 있을겁니다.
한 프레임내에서 여러 번 필요하지만 GetActorLocation()을 매번 호출할 필요가 없고, WorldLocation을 포함한 여러 데이터들은 FGlobalActorReplicationInfo에 접근할 때 Cache line 단위로 이미 가져왔을 것이므로 기본적으로 효율적입니다.

: Actor Instance에 대해 복제되는 정보 설정(class replication settings)을 mirror(반영)함으로써 override할 수 있음.
(나중에 더 설명할게요)
→ CDO로 부터 받아온 Replication 관련 정보를 여기에 모아둔 거임.

: Connection마다 갖는 ReplicationActorInfo
- FClassReplicationInfo
- FGlobalActorReplicationInfo
- FConnectionReplicationActorInfo
The other main thing is that every actor for every connection that it actually replicates to will have a connection specific piece of data associated with it.
또 다른 중요한 점은 실제로 리플리케이트되는 모든 연결의 모든 액터에는 해당 연결과 관련된 특정 데이터가 있다는 것입니다.
[ FConnectionReplicationActorInfo ]
uint32 StarvedFrameNum = 0;
마지막으로 복제받은 시점으로부터 frame 카운트
→ 5.1.1 기준, 복제받은 마지막 프레임이라는 명확한 의미를 주기 위해 LastRepFrameNum으로 변경된 것으로 보임.
모든 설정에 깊이 들어갈 필요는 없습니다.
중요한 점은 많은 노드가 포함된 Replication Graph가 있다는 것.
Replication lists를 생산해낸 뒤, global level, per every single connection에 관한 actor instances들에 해당하는 Class에 대해 associative data를 갖게 됨.
Replication Graph의 Code를 작성할 때 생각해야할 것은 "Connection에 대한 복제 여부 결정권"이 이제부터 Replication Graph에 있다는 것이다.
/* FConnectionReplicationActorInfo에서 중요하게 기억해야 할 것은, 각 Connection에 해당하는 Actor에 대해 Replication Period 를 관리한다는 겁니다. LastRepFrameNum, NextReplicationFrameNum, ReplicationPeriodFrame을 기억해두면 좋습니다.
*/
(28:00~)
[ Explanation in BasicReplicationGraph.cpp ]
[ UBasicReplicationGrpah::InitGlobalActorClassSettings() ]

주요점은 모든 UClass를 iterate 하며 CDO를 기반으로 data를 만들어 나가고 이후에 쓸 수 있게 저장한다는 것.
bAlywaysRelevant하거나 bOnlyRelevantToOwner인 경우 거리에 관계없이 복제받아야 하므로 CullDistanceSquared를 0.f로 설정.

ReplicationPeriodFrame : how many actual frame frames should be in between each replication call
Server Tick은 고정 또는 가변적일 수 있으며 시간당 소수점 횟수로 복제되는 형식으로 생각해야할 것이 아니라(not goint to be floating-point based on time) 몇 Frame마다 복제되는지 개념으로 생각해야 합니다.
3프레임마다 복제될 경우 초당 복제되는 frame은 20~30정도가 됩니다.

→ ServerTickRate에 비해 Actor의 NetUpdateFrequency가 작을수록 드물게 복제한다는 것임. 여기서 사용되는 Frequency는 N프레임마다 복제한다는 것인데, "나눠서 4가 나오면 4프레임마다 복제한다"로 이해하면 된다.

마지막에 GlobalActorReplicationInfoMap에 ClassInfo가 추가되고 난 뒤, 다양한 곳에서 여러 방면으로 사용 됨.
that's really all this thing has to do right now. It just has to populate up that list so the when we go to actually replicate an actor we say, "What class are you?" then "Oh you're this class. here's your data with this class and we use that data then to initialize the FGlobalReplicationActorInfo and then we will use that to initilialize the FConnectionReplicationActorInfo when it's necessary.
: 이 기능이 지금 해야 할 일은 그뿐입니다. 액터를 실제로 리플리케이트할 때 “당신은 어떤 클래스인가요?”라고 물으면 “아, 당신은 이 클래스입니다. 여기 이 클래스에 대한 데이터가 있고, 그 데이터를 사용하여 FGlobalReplicationActorInfo를 초기화한 다음 필요할 때 FConnectionReplicationActorInfo를 초기화할 것입니다.”라고 말할 수 있도록 목록을 채우기만 하면 됩니다.
[ UBasicReplicationGraph::InitGlobalGraphNodes() ]
자 이제 실제로 Graph에 Node를 추가할건데, 포트나이트 그래프 자료 사진을 보면서 이건 여기에 속하는 거구나 ~를 같이 이해하면 좋음. 각 노드들의 색깔로 Global, Per Connection, Shared 이런걸 연관지어 가는거임.
[ Comment from High level overview in ReplicationGraph.h ]
Nodes can be global, per connection, or shared (E.g, "Always relevant for team" nodes).
→ AddGlobalGraphNode(), AddConnectionGraphNode() in InitGlobalGraphNodes(), InitConnectionGraphNodes()

PreAllocateRepList();
→ In UE5, deprecated, Do nothing in code.

CreateNewNode<>() : Instantiate
CellSize : GridCell 하나 당 크기
SpatialBias : 코드 상 한계 점 중 가장 작은 좌표... spatialize할 맵 전체 크기를 specify 하는 것.
AlwaysRelevantNode : Always Relevant한 Actor가 뭔지 뱉어주기만 함 (항상 복제되어야 하므로)
그래서 실제로 이 노드에서 많은 일을 하진 않습니다.
[ UBasicReplicationGraph:: InitConnectionGraphNodes() ]

I don't know if i mentioned this already. but, so nodes on the graph like conceptually you think a lot of them is being global nodes. but a node can also be associated only with one connection or with a subset of connections so you can have a node that's only this on connection has or you could have a node that only a couple connections share so like a key like for example team based relevancy in a game like Paragon where certain actors are always relevant to their teammates there might be a team based like relevancy node and that all people on the same team would share. right?
제가 이미 언급했는지 모르겠지만 그래프의 노드는 개념적으로 많은 노드가 글로벌 노드라고 생각하지만 노드는 하나의 연결에만 연결되거나 연결의 하위 집합과 연결될 수도 있습니다. 그래서 이 연결에만 연결된 노드가 있을 수도 있고 몇 개의 연결만 공유하는 노드가 있을 수도 있습니다. 예를 들어 파라곤 같은 게임에서 팀 기반 관련성처럼 특정 액터가 항상 팀원과 관련성이 있는 경우 팀 기반 관련성 노드가 있고 같은 팀의 모든 사람들이 공유할 수 있습니다.
so InitConnectionGraphNodes() is knid of meant to like "hey, there's a new connection and would you like to create a graph node for it and this is how you do it ." which is you call CreateNode<> and then you call a AddConnectionGraph-Node() to actually "associate" it all.
this doing is adding it to a list so that when that connection gets replicated we make sure we ask that node what stuff it wants.
따라서 InitConnectionGraphNodes()는 “이봐, 새 연결이 생겼으니 그래프 노드를 만들고 싶으면 이렇게 하세요.”라는 의미로 CreateNode<>를 호출한 다음 실제로 모든 것을 연관화하기 위해 AddConnectionGraphNode()를 호출하는 것입니다.
이 작업은 연결을 목록에 추가하여 해당 연결이 복제될 때 해당 노드에 원하는 항목을 요청하는 것입니다.
(→ 여기서 associate라 함은 ReplicationGraphNode와 Connection을 파라미터로 받았으므로, 내부에서 TArray<TObjectPtr<UReplicationGraphNode>> ConnectionGraphNode에 추가하는걸 의미하는 것 같다.)
so these three function (InitGlobalActorClassSettings(), InitGlobalGraphNodes(), InitConnectionGraphNodes()) set the graph up and craete the nodes and all that other stuff.
따라서 이 세 가지 함수(InitGlobalActorClassSettings(), InitGlobalGraphNodes(), InitConnectionGraphNodes()는 그래프를 설정하고 노드 및 기타 모든 것을 생성합니다.
Next two functions are RouteAddNetworkActorToNodes() and RouteRemoveNetworkActorToNodes().
다음 두 함수는 RouteAddNetworkActorToNodes() RouteRemoveNetworkActorToNodes() 입니다.
[ RouteAddNetworkActorToNodes(), RouteRemoveNetworkActorToNodes(), GetAlwaysRelevantNodeForConnection(), ServerReplicateActors() ]
This actually deals with routing the actor to populate the graph as actors come and go. and so you can see the function by the function signature it gives you the global actor replication info and we look at that and say actually....., I take that back let me see...
(Other that Next to the speaker) : it's kind of hard to see it.
Okay, sorry.
이것은 실제로 액터가 오고 가고 할 때 그래프를 채우기 위해 액터를 라우팅하는 것을 처리합니다. 따라서 함수 시그니처를 통해 FGlobalActorReplicationInfo를 제공하는 함수를 볼 수 있으며 실제로.....(잠시 코드 좀 읽을게요)
So the way basically in graph works is it just looks at like the exisiting properties on the actual actor instance itself. it just looks at bAlwaysRelevant says if you're always relevant and I'm going to route you to the AlwaysRelevantNode. if you're only relevant to the owner, I'm gonna route you to the ActorsWithoutNetConnection..
그래프가 기본적으로 작동하는 방식은 실제 액터 인스턴스 자체에 존재하는 프로퍼티들을 보는 것입니다. bAlwaysRelevant가 true라면 AlwaysRelevantNode로 라우팅하고, bOnlyRelevantToOwner가 true라면 ActorsWithoutNetConnection으로 라우팅합니다.
Otherwise it's going to add you to the Spatialization Node and it calls this function which can't quite explain why it call this one and not the other ones kinda have to work our way into that but the main points at the route these routing functions are like high-level, actors registered or unregistered you got to add it or remove it from the graph knows yourself.
And.... that's actually kind of i think... okay, so now I guess i can explain the way that the AlwaysRelevant_ForConnection node works.
그렇지 않으면 Spatialization Node에 추가하고 이 함수를 호출하는데, 왜 이 함수를 호출하고 다른 함수는 호출하지 않는지 설명할 수는 없습니다만, 이 라우팅 함수의 주요 포인트는 액터를 register하거나 unregister하면 그래프에서 추가하거나 제거하게 되는 High Level 같다는 것을 아마 알고 계실겁니다.
그리고.... 실제로는... 좋아요, 이제 AlwaysRelevant_ForConnection 노드가 작동하는 방식을 설명할 수 있을 것 같습니다.
In basic replication graph the problem here is that you know that this actor only wants to bOnlyRelevantToOwner but I might not have the owner yet. right? when it's actually spawned it you may not actually have assigned its owner yet. I tried to build this to just be a liitle bit resilient to that so you kind of when you get registered, you don't actually go directly to know you going to this list for actors without Owner because I don't have a NetConnection with them yet. then in our version of ServerReplicateActors() is called in here before we call the main replication graph version we're gonna go through that list and try to find see if these guys have owners if they have owners then we'll then notice then we'll get them we'll call Get AlwaysRelevantNodeForConnection() and say and then pass it off to him and now he's like kind of his routing is now officially done. so that's hopefully that made that part make sense. but it's like i say in the end, we're just trying to get actors to the right nodes and then once they're in there, they'll be pulled out during the "Real" ServerReplicateActors() and then replicate actors though actor channels would be created, replicate actor will be called and the channels will be closed when necessary.
Basic ReplicationGraph에서 문제는 이 액터가 bOnlyRelevantToOwner만 원한다는 것을 알고 있지만 아직 Owner가 없을 수 있다는 것입니다. 그렇죠? 실제로 생성될 때 Owner를 아직 할당하지 않았을 수 있습니다.저는 이것을 약간 회복성 있게 구축하려고 노력했기 때문에 등록될 때 실제로 Owner가 없는 액터의 이 목록으로 직접적으로 바로 이동하지 않습니다.아직 그들과 NetConnection이 없기 때문입니다.그런 다음 ServerReplicateActors() 버전에서 메인 ReplicationGrpah 버전을 호출하기 전에 해당 목록을 살펴보고 이들에게 Owner가 있는지 확인합니다.Owner가 있으면 알아차리고 가져올 것입니다. Get AlwaysRelevantNodeForConnection()을 호출하고 말한 다음 그에게 전달하면 이제 그의 라우팅이 공식적으로 완료된 것과 같습니다. 그래서 그 부분이 의미가 있기를 바랬습니다. 하지만 결국 제가 말했듯이, 우리는 단지 액터를 올바른 노드로 이동시키려 하고, 일단 액터가 거기에 들어가면 "실제" ServerReplicateActors()에서 액터를 끌어오고 액터 채널이 생성되면 Actor를 Replicate하는 실질적인 부분이 호출되고 필요할 때 채널이 닫힐 겁니다.

/* : Spawn됐을 때 아직 Owner가 할당되지 않았을 수도 있음. 그래서 register되면 NetConnection이 없으므로 Actor list로 곧바로 가지않고, ServerReplicateActors를 override해서 NetConnection이 생길 때 까지 계속 for문을 돌림. 생긴다면 ActorsWithdoutNetConnection에서 1개씩 지워나가며 다 지워졌다면 이제 Super::ServerReplicateActors()을 실행시킨다.
사실 입문 단계부터 스페셜 케이스를 언급하게 된건데, AlwaysRelevant일지라도 Owner가 할당되지 않았을 경우에 예외 핸들링을 해줘야 하기 때문에 BasicReplicationGraph에서 예제코드를 만들어준 것이라 보면된다.
*/
[ Explanation of Spatialization in High-Level-Example ]
Let's Spatialization stuff real quick.
this space flow stage the way Spatialization works right now is a grid system.
we actually had an octree implementation at one point. and there were kind of actually some downsides to that and maybe i can get to them in a little bit but the main point is like so it's just basically a grid.
Spatialization에 대해 간단히 살펴보겠습니다.
이 공간 흐름 단계에서 현재 공간화가 작동하는 방식은 그리드 시스템입니다.
한때는 옥트리를 구현한 적도 있었는데, 거기에는 몇 가지 단점이 있었는데 나중에 설명할 수 있겠지만 요점은 기본적으로 그리드라는 점입니다.

대부분의 사람이 오해하는 점은 바로 이겁니다.
상자가 그리드 내에 있고, 나도 그리드내에 있다면 상자를 복제받을 수 있겠다라고 생각합니다.
그리고 상자가 있는 그리드에 없다면 상자를 복제받을 수 없겠다고 생각합니다.
이건 절대적으로 Spatialization이 작동하는 방식이 아닙니다. 이건 잘못된 접근 방식이에요.
가령 상자가 그림처럼 그리드 좌측상단 끝에 가깝게 있고, 내 캐릭터가 그리드의 좌측상단 꼭짓점위에 걸쳐있다고 생각해봅시다. 그럼 아무리 가까워도 상자를 복제받지 못한다는건데 이건 이치에 맞지 않습니다.
실제 작동하는 방식은 이겁니다.

상자에 파란 범위 원이 있고, 범위 원 내에 걸치는 그리드라면, 그러니까 지금 별이 표시된 그리드라면 상자를 복제받을 가능성이 있는겁니다. 상자만이 아니라 여러 Cell에 수많은 플레이어, 나무, 빌딩 등 액터가 섞여있다고 가정합시다. 비유하자면 결국 일부만을 복제받는 미니 복제 월드를 생성하는 것입니다. 그러니까 원안에 있는 Cell안에, 노란색 위치에 들어가게 된다면 복제해야하는 아주 작은 Actor List만 얻게 되고, 확실히 당신이 모르는 Junk는 없을 겁니다.
이제, 주황색 위치에 있다면 distance culling이 발생해야합니다. 주황색이 있는 Cell에서 파란색 원안에 들어가는, 우측상단 끝부분에 있다면 상자를 복제받을 수 있습니다.
그러나, 주황색 위치에 있다면 상자를 복제받아선 안된다는 겁니다. Replication Graph로 부터 return 됐다고 하더라도 복제된다는 확신이 없습니다. 하나의 Phase가 더 남아있어요. 얼마나 멀리있는지 Distance를 체크합니다.
Replication Graph로 부터 return된 List를 곧바로 복제하지 않고 Prioritize를 해야 합니다.
Rep Graph의 밖에있는 Polling Phase는 실제로 Prioritize 하지 않습니다. ← (// : 확실한 의미는 알기 힘드나, 별이 찍힌 그리드에 속하지 않은 액터들을 Polling Phase라고 표현했고, 이것들은 RepList에 들어가지않아 Prioritize 되지 않으므로, 별이 찍힌 그리드에 속한 액터들에 한해 Prioritize를 한다는 의미인듯 하다.)
return된 모든 lists들을 가져와서 Prioritize하고 그것들을 정렬하고 replicate합니다. 그래서 우리가 prioritizing 하고 sorting할 때, "너는 너무 멀기 때문에 신경쓰지 않을거야"라고 말할 수 있는 일이 발생하는 additional Culling stuff가 있습니다.
[ 부가 설명 ]
/* : 여기서 Dave 선생님이 설명하는 부분 중 "additional Culling stuff"는 GridSpatialization2D 노드가 하는 일이 아니라 이후 복제에서 일어나는 작업을 얘기합니다. 이 부분에 대해서 궁금하다면 UReplicationGraph::ReplicateActorListsForConnections_Default() 를 보세요. "// Distance Scaling" 주석을 보면됩니다. 여기서 말하는 Prioritize는, 전통적인 Replication 방식에서 사용되는 NetPriority를 통한 정렬을 말하는 것이 아닙니다. 그 전에 이미 Replication Graph의 복제 함수를 대신해서 호출한 것입니다. 결국 최종 목적은 같지만 실제로 커스텀된 각종 Factor에 따라 합산된 최종 Factor를 기반으로 Sort하는걸 말합니다. 엔진 주석에서도 프로젝트(게임)의 특성에 따라 Factor들을 커스터마이징하면 좋다고 나와있습니다. 정렬된 배열을 순차적으로 앞 element 부터 복제하면서 만약 해당 NetConnection에 대한 BandWidth Limit를 초과하면(Saturation) 이후의 element들은 복제하지 않습니다. 서버 입장에서 CPU Time을 낮추기 위해 Connection마다 최대한 고르게 복제해야 하니까요. Bandwidth Limit를 판단하는 부분이 궁금하다면 UReplicationGraph::IsConnectionReady() 를 보세요. 기존 Replication 방식에도 존재하듯이, 이론상 영원히 복제 받지 못하는 Starvation이 발생할 수 있습니다. 그래서 위에서 말한 Factor들 중에 마지막으로 복제된 Frame을 계속 카운트하고 확인하는 Starvation Factor가 존재합니다.
*/
Q) 왜 이런(grid, distance check) 일을 하는건가요?
A)In Fortnite, there' gonna be like you know 45000 actors that are just completely eating we're near you and you're gonna 45000 times and 100 connections like you that's just it does add up like that's why that's stuff does not scale so you kind of do have to do both you get the kind of the broad phase calling where you just here's a very serious like it's 1% of the know maybe a little bit more than one, it's like five percent of it all the replicated actors. you're getting a much smaller subset of that then you still blaze through it and you still have to do that the next step.
포트나이트에서는 45000개의 Actor가 우리 주변을 완전히 먹어치우고 있고 45000개의 액터, 100번의 연결이 있는 것처럼 합산(Connections * Actors)되는 거죠. 그래서 그런 건 스케일(부하를 처리하는게)이 안 되니까 두 가지를 다 해야 해요. 여기서 당신은 1%만 알게되는것, 어쩌면 더 많은 5%인 일부의 복제된 Actor들만 알게되는 것은 매우 중요합니다. 훨씬 더 작은 하위 집합을 얻는 것이고 여전히 그것을 통해 빠르게 처리하고 다음 단계에서 여전히 그렇게해야합니다.
/* NetConnection이 1개에 Actor가 45000개라면 전부 복제할 때 45000번이 필요하다. 그런데 NetConnection이 100개라면? 45000개에 100이 곱해져서 복제하는데 소요되는 CPU Time이 기하급수적으로 증가하는 것이다. (Bottleneck) */
(40:50 ~)
[ FortRepGraph Example ]
ShooterGame의 Replication Graph는 Fortnite의 라이브 RepGraph와 상당히 비슷합니다.
(42:50~)
a lot of actors that are always relevant to a given connection you don't acutally need to like maintain a persistent list .well it's good to maintain a persistent list but it's not necessarily. you can usually like come up with that list just by knowing what connection it is like once you have the PlayerController. just as an example you once you have the PlayerController you can get Pawn and then from the Pawn you can get like if it has a weapon or its inventory system or you know all these kind of depedent actors that are OnlyRelevant to him. so rather than like putting those actors through the same like machinery you just can kind of like pull them out as we replicate. so let's see if i can find that.
here's like the UFortReplicationGraphNode_Always_Relevant_ForConnection::GatherActorListsForConection(const FConnectionGatherActorListsParameter& Params).
주어진 Conenction에 AlwaysRelevant인 많은 액터는 실제로 영속적인 목록을 유지할 필요가 없습니다. 영속적인 목록을 유지하는 것이 좋지만 반드시 그럴 필요는 없습니다. 예를 들어 PlayerController가 있으면 연결이 어떤지 아는 것만으로 그 목록을 만들어낼 수 있습니다. PlayerController가 있으면 Pawn을 얻을 수 있고 Pawn에서 무기나 인벤토리 시스템이 있는지 또는 그와만 관련이 있는 이러한 모든 종류의 종속 액터를 알 수 있습니다. 따라서 이러한 액터를 동일한 기계에 넣는 대신 복제할 때 끌어낼 수 있습니다. 찾을 수 있는지 보겠습니다.
다음은 UFortReplicationGraphNode_Always_Relevant_ForConnection::GatherActorListsForConection(const FConnectionGatherActorListsParameter& Params)입니다.
(// : 함수를 찾아갔지만 코드가 많아서 설명할게 많다고 해서 화제를 바꿈.)
I think one point I haven't made yet is that ReplicationGraph some of the things that we are giving up are I was kind of railing a little bit on the virtual functions early. and I didn't make it totally clear that like ReplicationGraph does not call those virtual functions at all like IsNetRelevant() is basically not used at all in ReplicationGraph. because you don't have these virtual functions that the actors can implement and you have this rigid system.
there's still things that change throughout the game that have to change that stuff and ReplicationGraph either it's the node and where the actor is in the nodes or it has to change some of those settings that I was talked about that associative data that I was talking about. and so to do that usually what it will do is I have the game code invoke these events that say "Hey something changed" so just as an example like vehicles.
If you when you get in a vehicle you call this OnVehicleChange Delegate and anyone that wants to listen to that this vehicle change event can listen to it so the ReplicationGraph listens to that and when a ReplicationGraph finds out that you've changed vehicles, it will put that new vehicle in it'll do what it needs to do which in this case the vehicle goes on to the DependentActorLists for that actor.
I haven't explained with DependentActorLists yet either. so the DependentActorList is also kind of a new concept in ReplicationGraph which is pretty simple. it just means "Hey, this actor does not replicate on its own. it only replicates if another actor if it's only an actor replicates." so like the weapons are the great example are the vehicles where we're not gonna spatialize the weapons individually if there's no point in doing that they're already there they're relevant if the pawn is relevant that's all you need to care about.
and the old system had that only relevant to i think there was an option the old system to only use the owner's relevancy(bNetUseOwnerRelevancy) but it's still a bit different in the sense that like the weapon doesn't even get added into the graph and it doesn't go through all this like machinery. it just kind of pops out at the end where it just says "hey this pawn is gonna replicated and oh look it has some dependent actors and they're gonna replicate to right behind it all the time". it also is nice because that guarantees order of replication almost guarantees. I shouldn't 100% because they could potentially be split over packets and that first time it could be dropped. so that's something I want to address at some point. but what the main point is for the most part the pawn will always replicate before like the weapons or it's other dependent actors.
so yeah, Fortnite's game code has to like tell ReplicationGraph a lot of times when things change like if DependentActorList is the best example. but i think there's probably some other examples of like us changing and for example Cull Distance will have to change on certain actors. i mean even for example like during the lobby phase of Fortnite, some of those replication like settings and frequencies and stuff we kind of modified them a little bit too because there's so many people so close together that performs pretty badly. so it kind of some of those that stuff gets like real throttled down in the lobby but then when game starts, it we reset it so that's like the game mode doesn't that when it changes those phases and it's all sort of that's stuff.
아직 언급하지 않은 점이 하나 있는데, ReplicationGraph에서 포기하고 있는 것 중 하나는 제가 가상 함수에 대해 초반에 약간 비판했던 부분입니다. 그리고 ReplicationGraph가 IsNetRelevant()와 같은 가상 함수를 전혀 호출하지 않는다는 것을 완전히 명확하게 밝히지 않았습니다. 이는 액터가 구현할 수 있는 가상 함수가 없고 엄격한 시스템이 있기 때문입니다. 게임 전체에서 변경해야 하는 것들이 여전히 있고, 이러한 것들을 변경해야 하며, ReplicationGraph는 노드와 액터가 노드에 있는 위치이거나 제가 말했던 연관 데이터 중 일부를 변경해야 합니다. 그래서 그렇게 하기 위해 일반적으로 하는 일은 게임 코드에서 "이봐요, 뭔가가 바뀌었어"라고 말하는 이러한 이벤트를 호출하는 것입니다. 예를 들어 차량과 같은 것입니다.
차량에 탑승했을 때 이 OnVehicleChange Delegate를 호출하면 이 차량 변경 이벤트를 듣고 싶어하는 모든 사람이 이를 들을 수 있으므로 ReplicationGraph가 이를 듣고 ReplicationGraph가 차량을 변경했다는 것을 알게 되면 해당 차량을 넣어 필요한 작업을 수행하게 되는데, 이 경우 차량은 해당 액터의 DependentActorLists로 이동합니다. 아직 DependentActorLists에 대해 설명하지 않았습니다. 따라서 DependentActorList도 ReplicationGraph의 새로운 개념으로 매우 간단합니다. "이 액터는 스스로 복제하지 않습니다. 다른 액터가 복제하는 경우에만 복제합니다."라는 의미입니다. 무기와 같은 좋은 예는 차량인데, 무기를 개별적으로 공간화하지 않을 것입니다. 그럴 필요가 없다면 무기는 이미 거기에 있고 폰이 관련이 있다면 그게 신경 써야 할 전부입니다. 그리고 이전 시스템은 제 생각에 소유자의 관련성만 사용하는(bNetUseOwnerRelevancy) 옵션이 이전 시스템에 있었지만, 무기가 그래프에 추가되지 않고 기계처럼 모든 것을 거치지 않는다는 점에서 여전히 약간 다릅니다. 그냥 끝에서 튀어나와서 "이 폰이 복제될 거야. 오, 종속된 액터가 있고 그들은 항상 바로 뒤에 복제될 거야"라고 말합니다. 또한 복제 순서를 거의 보장하므로 좋습니다. 100% 확신할 수는 없는데, 여러 패킷으로 분할될 가능성이 있고 처음에는 삭제될 수 있기 때문입니다. 그래서 언젠가는 해결해야할 사항입니다. 하지만 가장 중요한 요점은 대부분 폰이 무기나 다른 종속된 액터보다 먼저 복제된다는 것입니다.
그래서, 포트나이트의 게임 코드는 상황이 변할 때 ReplicationGraph에 여러 번 알려야 합니다. 예를 들어 DependentActorList가 가장 좋은 예지만, 특정 액터에서 NetCullDistance가 변경되어야 하는 경우와 같은 다른 예도 있을 수 있습니다. 예를 들어 포트나이트의 로비 단계에서도 설정과 Frequency 같은 일부 리플리케이션은 너무 많은 사람이 너무 가까이 있어서 성능이 좋지 않아서 약간 수정했습니다. 그래서 로비에서는 실제로 속도가 느려지지만 게임이 시작되면 게임 모드가 그 단계를 변경하지 않도록 리셋하는 등의 작업을 수행합니다.
(// : 포트나이트 로비 단계 : PUBG의 시작섬 처럼 매치가 잡힌 후, 매치 시작 직전 한 구역에서 수십명의 플레이어가 노는 1분정도의 대기시간을 의미하는 듯)
Ryan(Network Lead Programmer) :
And to be clear a lot of benefit of doing that model kind of having the game code push this setting changes into replication system is that in contrast to the legacy replication system where that system was kind of pulling for these settings every frame or multiple times a frame if it had to replicate the same actor to multiple connections sometimes it was pulling that data through possibly one of the virtual functions that Dave mentioned and you know that's like you said before it's harder to kind of control the performance of that and a lot of these things don't change frequently enough where we actually needed to do that so this was a big efficiency win for those reasons.
게임 코드가 이 세팅 변경 사항을 리플리케이션 시스템에 푸시하는 이 모델을 사용하면 많은 이점이 있는데, 기존 리플리케이션 시스템에서는 동일한 액터를 여러 연결에 리플리케이트해야 할 경우 매 프레임 또는 여러 프레임에 걸쳐 세팅을 가져오는 것과는 대조적입니다. 때때로 데이브가 언급한 가상 함수 중 하나를 통해 데이터를 가져왔고, 앞서 말씀하신 것처럼 그 성능을 제어하기가 더 어렵고 실제로 그렇게 해야 할 만큼 자주 변경되지 않는 경우가 많았기 때문에 이러한 이유로 효율성이 크게 향상되었습니다.
Dave :
I also I personally like that it's all kind of here like although all the real nitty-gritty of like replication at this level like obviously replicated properties and RPCs and the game how the game code net replicates is in those classes but this sort of like how fast is the server going able to replicate everything is kind of like all controlled here so you get this nice holistic view.
또한 저는 개인적으로 이 레벨에서 리플리케이션의 핵심인 프로퍼티와 RPC, 게임 코드넷이 리플리케이트하는 게임 방식은 해당 클래스에 있지만 서버가 모든 것을 얼마나 빨리 리플리케이트할 수 있는지와 같은 모든 것이 여기에서 제어되므로 전체적인 뷰를 얻을 수 있다는 점이 마음에 듭니다.
아직 다루지않은 주요 사항에 대해 알아보겠습니다.
Grid Cell here is actually a bit more complicated than just a list of actors that were that are within the grid we still have to still subdivide them based on whether there's they don't move they're Static. they never move and so we never have to update their position basically frame to frame. if they're always moving are usually moving like pawns and bullets and vehicles and that sort of stuff and those actors we are continuously once per frame per actor we're figuring out if it's changed cells and that's they even that alone is a huge win, right? it's way easier to go through all your Dynamic actors and see are they sail still in the same cell doing that one time rather than doing stuff that's per connect and per actor you. whatever altering it wasn't and then they're still like dormant actors where for example a weapon pickup which when it spawns it actually can move it can fall and it can roll down a hill on that then that sort of thing. but once it settles it's basically nothing else is going to move it. so it kind of goes back and forth between a move being able to move and not being able to move at all.
I mean in some ways like that pawns kind of stand still but hey could start moving at any time. so you wouldn't really want to like take them on and off that Static versus Dynamic List.
Because they always could potentially move but once like the pickup stops moving it's going to always stop moving and so that's kind of what I mean here by the Dormancy controls whether it's static or dynamic is kind of what it means at that level this is all in Grid Cell 2D node.
여기의 그리드 셀은 그리드 내에 있는 액터 목록보다 실제로 조금 더 복잡합니다.우리는 여전히 그들이 움직이지 않는지, Static인지에 따라 그들을 세분화해야 합니다. 그들은 결코 움직이지 않으므로 기본적으로 프레임별로 위치를 업데이트할 필요가 없습니다. 그들이 항상 움직이는 경우, 일반적으로 Pawn, 총알, 차량과 같은 것들이 움직이고 그러한 액터는 프레임당 한 번씩 액터당 지속적으로 셀이 변경되었는지 알아내고 있습니다. 그것만으로도 엄청난 승리입니다, 맞죠?
모든 동적 액터를 살펴보고 그들이 여전히 같은 셀에 있는지 확인하는 것이 Connection마다 또는 Actor마다 작업을 수행하는 것보다 훨씬 쉽습니다. 변경되지 않는 경우 Dormant 액터와 같습니다. 예를 들어 Weapon Pickup은 생성될 때 실제로 움직일 수 있고 떨어질 수 있으며 언덕 아래로 굴러갈 수 있습니다. 하지만 일단 정착하면 기본적으로 다른 것은 움직이지 않습니다. 그래서 움직일 수 있는 것과 전혀 움직일 수 없는 것 사이를 왔다 갔다 하는 셈이죠.
어떤 면에서는 Pawn이 가만히 서 있지만 언제든지 움직이기 시작할 수 있다는 뜻이에요. 그래서 Static과 Dynamic 리스트 사이에서 Pawn을 넣었다 뺐다 하고 싶지 않을 거예요. Pawn은 항상 움직일 수 있지만 픽업은 한 번 움직이지 않기 시작하면 계속 움직이지 않게 되거든요. 그래서 여기서 Dormancy가 Static인지 Dynamic인지 컨트롤하는 것은 그 레벨에서 의미하는 바는 이 모든 것이 Grid Cell 2D 노드 내에 있다는 겁니다.
[ 부가 설명 ]
/* 위 설명은 GridSpatialization2D에 라우팅되는 Actor가 어떤 종류의 노드로 들어가야할지 대략적으로 설명합니다.
포트나이트를 실제로 플레이해보면 총알, 무기등 월드에 떨어진 아이템(Pickup)은 기본적으로 가만히 있지만, 내리막길에 떨어지면 중력에 따라 쭉 ~ 미끄러집니다. 스스로 움직일 수 없는 액터가 이럴 일이 있냐고 생각할 수도 있는데, 캐릭터가 공중이나 높은 곳에서 죽으면 가지고 있던 아이템들을 주위에 한번에 쏟아내며 죽기 때문에 이런 일이 꽤 발생합니다. 더군다나 게임 특성상 후반으로 갈수록 벽을 수십 수백개 지으며 높은 곳에서 전투할 확률이 매우 높기 때문에 이런 케이스를 언급한 것 같습니다. 그러니까 요점은 Weapon Pickup같은 액터는, 스스로 움직일 수 없는 Static이더라도 외부의 영향으로 인해 잠재적으로 움직일 수 있는 것이기 때문에 AddActor_Dormancy()를 통해 추가됩니다. 그런데 이것은 AddActor_Static, AddActor_Dynamic과 달리 Dormancy List라는 것이 존재해서 여기에 추가하는 것이 아닙니다. 추가되었을 때 Dormancy 유무에 따라 Static list와 Dynamic list 중 하나로 들어가게되고, Dormancy가 변경되면 델리게이트를 이용해서 2개의 list사이를 왔다 갔다 합니다. 가끔씩 GridCell의 경계를 넘나드는 것이 이론상 가능하기 때문인거죠.
그러니까 여기에 라우팅되는 모든 액터는 Static또는 Dynamic이므로 여기서 추가되거나 삭제될 일이 없어 어떠한 경우에도 Grid Cell 2D 노드에 속한다는 뜻입니다. */
여기서 다루지 못한 사항은 Streaming Levels입니다.
Streaming levels error that was actually another big pain point in the old system is.
First the way that streaming levels and replication work are usually historically as I've always been is the clients tell the server I'm loading this level and they tell them the server when they've unloaded the level. I mean i think the server can issue explicit, "you should load this level now" or "you should unload it" commands, but that doesn't that's not the way how Fortnite works is just we have these basically have these actors in the map and as you get close to them or far away from them we stream them in or we stream things out. and although the server could kind of guess and be like i think he's here and so i think these are the levels he has loaded or he doesn't have loaded. all the different platforms we support and different like hardware and hard drive speeds and that sort of thing that you can't really rely on the sever, shouldn't really rely on what state what levels the client has loaded. at any given point it's better for him to just tell the clients to just tell you so whatever backing up actors had within streaming levels. we don't want to replicate stuff to a client if he doesn't have the level loaded. the code is resilient to that, because of like networky race conditions and things being in flight when levels are loaded or unloaded. so the server the system can handle that but it's inefficient to like replicate stuff and have it just be like I'm not gonna do it cuz i don't have the level of this thing as in yet.
So we do additional stuff on streaming levels. and the old system was slow. because to handle this it would every actor for every connection before you did anything you had to say what level is this actor in and then you have to say well here are the levels that this guy has loaded and does he have that level loaded right now. and that's actually kind of a lot of work there's like 30 plus maybe 40 or 50 even streaming levels in Fortnite so that would be a list or I think we moved it to a TMap or TSet at some point. but it's still like it's just all this bookkeeping that's just very redundant it doesn't really often change. so, that actually was one of the hot spots in the old system especially when we went to the streaming levels and so the replication graph kind of like the nodes there at least our Shipping here with 4.20 they give you some options for how to do this in a better way.
and so basically the way that it does work is "rather than keeping one big list of a bunch of actors" that may or may not be in different streaming levels, we won't at these lower at these kind of leaf nodes in the graph. it further gets subdivided and said "okay these are the actors that are not in these are the Dynamic actors that are just in the persistent level and then here's a list for all the actors that are in this streaming and here's one that's here is a list for all the actors in another streaming level." and then when you go to pull the Actor Replication list for those connections for a connection, you say "you basically do the culling or the filtering out at that level", you just say "do you have this level loaded if you do if you don't even give him this list and these actors". because he doesn't need to know about any of them. so the calling basically just happens like ideally one time and as early as possible and so you have is the least amount of wasted work. so I think i show you real quick what kind of looks like.
실제로 이전 시스템에서 또 다른 큰 문제점이었던 스트리밍 레벨 오류는 다음과 같습니다.
첫째, 스트리밍 레벨과 복제가 작동하는 방식은 일반적으로 제가 항상 그래왔던 것처럼 클라이언트가 서버에 이 레벨을 로드하고 있다고 알리고, 클라이언트가 레벨을 언로드했을 때 서버에 알리는 것입니다. 제 말은, 서버가 "지금 이 레벨을 로드해야 합니다" 또는 "언로드해야 합니다"라는 명령을 명시적으로 내릴 수 있다고 생각하지만, 그게 포트나이트가 작동하는 방식이 아닙니다. 기본적으로 맵에 이러한 액터를 두고, 그들에게 가까이 가거나 멀리 떨어지면 그들을 스트리밍하거나 스트리밍합니다. 그리고 서버는 추측할 수 있고, 그가 여기 있다고 생각하고, 그래서 이것이 그가 로드했거나 로드하지 않은 레벨이라고 생각합니다. 우리가 지원하는 모든 플랫폼과 하드웨어, 하드 디스크 속도와 같은 다른 것들, 그리고 서버에 의존할 수 없는 그런 종류의 것들은 클라이언트가 로드한 레벨의 상태에 의존해서는 안 됩니다. 어느 시점에서든 클라이언트에게 스트리밍 레벨 내에서 백업 액터가 가진 모든 것을 말해달라고 말하는 것이 더 좋습니다. 우리는 클라이언트가 레벨을 로드하지 않았다면 클라이언트에 어떤 것이든 복제하고 싶지 않습니다. (// : 레벨이 아직 로드되지않았는데 복제되어 액터만 보이는건 이치에 맞지 않으니까요.) 네트워크 Race Condition과 레벨이 로드, 언로드될 때 진행되는 기능이기 때문에 코드는 이런 부분에 대해서 탄력적입니다. 따라서 서버 시스템은 이를 이전 방식대로 처리할 수는 있지만, 무엇이든 복제하고 아직 이 레벨이 없기 때문에 복제 하지 않을 것이라고 말하는 것은 비효율적입니다.
그래서 우리는 스트리밍 레벨에서 추가적인 작업을 합니다. 이전 시스템은 느렸습니다. 이를 처리하려면 모든 연결에 대한 모든 액터가 어떤 레벨에 있는지 말해야 했고, 그러면 이 사람이 로드한 레벨이 여기 있고 지금 그 레벨을 로드했는지 말해야 했습니다. 그리고 사실 거기에는 많은 작업이 있습니다. 포트나이트에는 30개 이상, 어쩌면 40개 또는 50개의 스트리밍 레벨이 있습니다. 그래서 그걸 관리하는건 단순한 List였습니다. 아니면 어느 시점에서 TMap 또는 TSet으로 옮겼을 겁니다. 하지만 여전히 매우 중복되는 모든 북키핑(자료구조에 일일이 기록해서 거대하게 보관하는 것)과 같습니다. 실제로 자주 변경되지 않습니다. 그래서 특히 스트리밍 레벨로 이동했을 때, 실제로 그 기능은 이전 시스템에서 핫스팟 중 하나였습니다. 그래서 적어도 4.20 버전의 Shipping에서 노드들이 들어있는 Replication Graph는 이를 더 나은 방법으로 수행하는 방법에 대한 몇 가지 옵션을 제공합니다.
기본적으로 작동하는 방식은 "다른 스트리밍 레벨에 있을 수도 있고 아닐 수도 있는 여러 액터의 큰 목록을 유지하는 대신" 그래프의 하나의 리프 노드에서 모여있지 않을 겁니다. 거기서 더 세분화되어 "좋아요, 이것들은 퍼시스턴트 레벨에 있는 다이나믹 액터가 아닌 액터입니다. 그리고 여기 이 스트리밍에 있는 모든 액터의 목록이 있고 여기 다른 스트리밍 레벨에 있는 모든 액터의 목록이 있습니다."라고 합니다. 그런 다음 연결에 대한 ActorReplicationList를 끌어올 때 "기본적으로 해당 수준에서 컬링이나 필터링을 수행합니다"라고 말하고 "이 목록과 이러한 액터를 제공하지 않더라도 이 수준이 로드되어 있나요?"라고 말합니다. 그는 그들에 대해 알 필요가 없기 때문입니다. 따라서 호출은 기본적으로 이상적으로는 한 번, 가능한 한 일찍 수행되므로 낭비되는 작업이 최소화됩니다. 그래서 어떤 모습인지 아주 빨리 보여드리겠습니다.

/* [ Lyra example ]
"Client가 로드, 언로드될 때 마다 서버에게 말하는게 낫습니다." 부분을 참고하려면
ULevelStreaming::ServerUpdateLevelVisibility()에서 PlayerController->ServerUpdateLevelVisibility()를 보세요.
다음과 같이 호출됩니다.
- ULevelStreaming::ServerUpdateLevelVisibility()
-- APlayerController::ServerUpdateLevelVisibility()
--- UNetConnection::UpdateLevelVisibility()
---- UNetConnection::UpdateLevelVisibilityInternal()
----- UNetReplicationGraphConnection::NotifyClientVisibleLevelNamesAdd()
------ OnClientVisibleLevelNameAdd.Broadcast();
====== OnClientLevelVisibilityAdd()
====== OnClientLevelVisibilityRemove()
클라이언트에서 호출되는 ServerRPC인데, 내부에서 NetConnection을 통해 UpdateLevelVisibility()를 호출하고, 그 안에서 ReplicationConnectionDriver->NotifyClientVisibleLevelNamesAdd()가 호출되면 ReplicationGraph내에 있는 OnClientVisibleLevelNameAdd 델레게이트를 Broadcast해서 바인드되어있던 OnClientLevelVisibilityAdd() 함수를 통해서 ReplicationGraph는 로드, 언로드된 Level을 알 수 있게 됩니다. 이것을 ULyraReplicationGraphNode_AlwaysRelevant_ForConnection의 멤버 변수인 TArray<FName, TInlineAllocator<64>> AlwaysRelevantStreamingLevelsNeedingReplication 에서 저장하고 있습니다. */
(54:30~)
[ ReplicationGraph.h : UReplicationGraphNodeActorList ]
UReplicationGraphNodeActorList is kind of like you're sort of basic leaf node it contains it's a node in the graph that just contains conceptually what I just described, where it's actually not just one replication list it's so it's actually it's one replication list for the non streaming level actors and then it's a collection of actor lists that the streaming level actors will go in and so I think originally I kind of was only using I decided to build that I think it makes sense to have this node handle the streaming case and the non-streaming case even if your game doesn't have streaming levels like the overhead of like having this extra thing here is nothing.
UReplicationGraphNodeActorList 는 일종의 기본 리프 노드와 같은 것으로, 방금 설명한 것을 개념적으로 포함하는 그래프 의 노드입니다, 실제로는 하나의 복제 목록이 아니라 non-streaming level actors에 대한 하나의 복제 목록이고, streaming level actors가 들어갈 액터 리스트 모음(Collection of actor lists)이기 때문에 이 노드가 스트리밍 케이스와 비스트리밍 케이스를 처리하는 것이 합리적이라고 생각해서 만들기로 했습니다.
비록 스트리밍 레벨이 없는 게임에서도 이런 추가적인걸 소유하더라도 overhead가 발생하진 않을 겁니다.
(UReplicationGraphNode_ActorList에 있는 FActorRepListRefView ReplicationActorList와 FStreamingLevelActorListCollection StreamingLevelCollection에 대해 말하는 것.)

The main point being.. this is kind of all streaming level business is kind of all encapsulated into this guy and specifically it's actually this structure here this FStreamingLevelActorListCollection is which does all that stuff i just described.
중요한 점은.. 이것은 모든 스트리밍 레벨의 비즈니스가 이 친구 안에 캡슐화되어 있다는 것입니다. 특히 이 구조는 바로 FStreamingLevelActorListCollection으로, 제가 방금 설명한 모든 작업을 수행합니다.
[ FStreamingLevelActorListCollection::AddActor(const FNewReplicatedActorInfo& ActorInfo) ]
this is just finding what lists this actor should go in based on his streaming level. if you passed a actor into here if it didn't have a streaming level it will just go in the none streaming level list. and same with the Remove() and and the Reset().
so here. the Gather(), this is kind of the thing of the guys what I was just saying. so when you go to gather replication lists from for a given connection, these are the parameters that get passed in when you're gathering when you're doing exactly that.
This is the function that gets called, the parameters has this funciton called CheckClientVisibilityForLevel which that in the end just does you know, it just says hey "it is a little optimization because it checks the last one that we checked" because that's usually what it is but if it's not that. we go to there's just a TSet of FName that the actor has. These are the level names that the actor has loaded and so that's just kind of the quickness check to do so. okay I think there's enough on the streaming level stuff I think that's pretty much the basic idea there.
이건 스트리밍 레벨에 따라 이 액터가 어떤 목록에 들어가야 할지 찾는 것입니다. 스트리밍 레벨이 없는 액터를 여기에 전달하면 Non streaming level list에 들어갑니다. Remove()와 Reset()도 마찬가지입니다. 기본적으로 그렇습니다.
여기서 Gather()는 제가 방금 말한 것과 비슷합니다. 주어진 연결에 대한 복제 목록을 수집할 때, 수집할 때 전달되는 매개변수가 바로 그것입니다.
호출되는 함수가 인자로 가져오는 FCnnectionGatherActorListsParameter& Params에는 CheckClientVisibilityForLevel이라는 함수가 있는데, 결국에는 "마지막에 확인한 것을 확인하기 때문에 약간의 최적화입니다"라고 말합니다. 보통 그게 그거지만 그게 아니라면, 액터가 가지고 있는 FName의 TSet이 있습니다. 이것들은 액터가 로드한 레벨 이름이고, 그래서 그것은 그저 그렇게 하는 빠른 검사입니다. 스트리밍 레벨에 대한 내용이 충분하다고 생각합니다. 그게 기본적인 아이디어라고 생각합니다.
Amanda(Community Manager) : I feel like we're gonna have to turn this into a series. seems like there's a lot to cover that we haven't even...
Dave : scratched the surface here.. okay so if you ever use this here's my suggestion.
[ Fortnite Example In Action ]
ReplicationGraphDebugging.cpp has like a bunch of useful stuff that you can use to like inspect the state of UReplicationGraph and even change things on the fly and kind of like use this how you want.
ReplicationGraphDebugging.cpp에는 UReplicationGraph의 상태를 검사하거나 즉석에서 항목을 변경하고 원하는 대로 사용하는 데 사용할 수 있는 유용한 기능이 많이 있습니다.
(58:00~)
(ReplicationGraphDebugging.cpp : ReplicationGraph를 PIE LOG를 통해 TEXT로 형체를 파악할 수 있는 기능)
(1:02:00~)
[ Q&A Time ]
Q) They're wondering have we added any replication mode for replicating to a Spectator and there example was we'd like to look (CO Indiana's core) : owner and spec only
채팅창에 질문 보여주면서... Spectator에 관한 replication 질문
A) 엔진단에서 Spectator에 대해 내장된건 아무것도 없습니다. Spectator도 궁극적으로 게임내에서 replicated data가 필요한 또 하나의 entity입니다. ~~
Q) Does the allow them to prevent Multicast variables from briefly getting set beyond the range of the NetCullDistance?
→ MulticastRPC가 NetCullDistance를 넘어갈 경우 실행되지 않는 규칙이 있는데 이걸 넘어서 커스터마이즈할 수 있냐고 묻는 것 같습니다.
A) 이건 얘기하지 않았으니 정말 빠르게 설명드리겠습니다.
ReplicationGraph can also modify how RPC get routed. so specifically that would really only make sence for MulticastRPC
ReplicationGraph는 MulticastRPC가 route되는 방식또한 수정할 수 있습니다. MulticastRPC에 대해서만 해당됩니다.
[ UReplicationGraph::ProcessRemoteFunction() ]

ReplicationGraph::ProcessRemoteFunction() essentially hijacks that part of it, the routing of the RPC.
here's an example, this is how we handle MulticastRPC in the ReplicationGraph.

there's some extra stuff that kind of got out of here that, I can't quite get into i think with the time we have.
but, yes. if you want to customize Wayne and under what conditions and who a MulticastRPC goes to, you totally can do that with Replication Driver, not even ReplicationGraph but yes. even within ReplicationGraph you can change that however you want. you can have special rules and special relevany checks and do whatever you want to determine if who should get the RPC.
시간 관계상 자세히 설명할 수 없는 여기 코드를 벗어난 추가 내용이 몇 가지 있습니다.
하지만 답변은 YES입니다. Wayne과 멀티캐스트RPC가 어떤 조건에서 누구에게 전달되는지 사용자 정의하고 싶다면 ReplicationGraph가 아니라 Replication Driver를 사용하여 완전히 할 수 있습니다. ReplicationGraph 내에서도 원하는 대로 변경할 수 있습니다. 특별한 규칙과 특별한 관련성 검사를 통해 누가 RPC를 받아야 하는지 결정하는 데 원하는 모든 것을 할 수 있습니다.
/*
Dave 선생님이 말한 "ReplicationGraph::ProcessRemoteFunction() essentially hijacks that part of it, the routing of the RPC."가 어디서 일어나는지 궁금하다면, UNetDriver::ProcessRemoteFunction()을 보세요.

ReplicationDriver가 유효하다면 (ReplicationGraph가 구현되어 있다면) 중간에서 ReplicationDriver의 가상함수인 ProcessRemoteFunction()을 실행하고 return하고 있습니다. 구현되어 있지 않다면 default implementation으로 넘어갑니다.
*/
Q) A couple folks asked about "streaming sockets datagrams" all both.
A) If you're asking aobut general networking, I don't think that really has much to do with replication graph still. just sits on kind of it uses the existing kind of UDP network protocol that unreal networking has always used for gameplay replication and networking. it's kind of a separate topic.
But, if what you're wondering Unreal does, we use UDP datagrams for its gameplay networking.
일반적인 네트워킹에 대해 묻는다면, 저는 그것이 여전히 복제 그래프와 크게 관련이 있다고 생각하지 않습니다.
그저 언리얼 네트워킹이 게임플레이 복제와 네트워킹에 항상 사용해 온 기존의 UDP 네트워크 프로토콜을 사용하는 것일 뿐입니다. 그것은 별개의 주제입니다.
하지만, 당신이 궁금해하는 것이 언리얼이라면, 우리는 게임플레이 네트워킹에 UDP 데이터그램을 사용합니다.
(1:09:00~)
[ Potential of Replication Graph ]
Q : People are wondering what is the potential that the network, replication graph could handle, so right now obviously Fortnite supports 100 players but could we do 500 players... or 1000 players...?
A : it's really hard to say because it still matters on...
it depends what your target framerate is and what hardware you're running on and how many replicated properties you have, so there's like all these other different variables but I mean I would say at some point like if you try to do a 1000 players like that's at some point you probably got to either go multithreaded or multi server and Replication Graph might eventually be able to help you there or at least replication drivers potentially could, but I say kind of right now is shipped in 4.20 it's not, There's probably gonna be some limit that you hit that's somewhere above 100 probably less than a thousand.
Q) 언리얼엔진의 Replication Graph가 지원하는 네트워크의 잠재력은 어떨까요? 포트나이트가 지금 100명을 지원할 순 있지만, 어쩌면 500명 또는 1000명까지도...?
A) 대답하기 힘드네요. 왜냐하면 여러가지 변수가 있는데요...
목표 frame rate가 얼마인지, 서버가 실행되는 하드웨어가 무엇인지, 그리고 얼마나 많은 replicated property들이 있는지, 그래서 이같은 많은 다른 변수가 있습니다. 하지만 제가 말하고자 하는 바는, 어느 시점에 1000명의 플레이어를 넣으려 노력해본다면, 그 때는 멀티쓰레드나 멀티 서버로 가야할 겁니다. 그리고 Replication Graph가 결국 당신이 하려는걸 도와줄 수 있을지도 모르지만, 또는 최소한 Replication Driver가 잠재적으로 가능할 수도 있겠지만, 일단 4.20에 출시된 당장의 버전에선 불가능하다고 말하고 싶어요. 아마도 한계는 100명이상 1000명이하 일겁니다.
[ LyraReplicationGraph.cpp Comment's Note ]
=============== LyraReplicationGraph Replication ===============
[ Overview ]
This changes the way actor relevancy works. AActor::IsNetRelevantFor is NOT used in this system!
이것은 Actor Relevancy가 작동하는 방식을 변화시킵니다. AActor::IsNetRelevantFor은 이 시스템에서 사용되지 않습니다.
Instead, The ULyraReplicationGraph contains UReplicationGraphNodes. These nodes are responsible for generating lists of actors to replicate for each connection. Most of these lists are persistent across frames. This enables most of the gathering work ("which actors should be considered for replication) to be shared/reused. Nodes may be global (used by all connections), connection specific (each connection gets its own node), or shared (e.g, teams: all connections on the same team share). Actors can be in multiple nodes! For example a pawn may be in the spatialization node but also in the always-relevant-for-team node. It will be returned twice for teammates. This is ok though should be minimized when possible.
대신에, ULyraReplicationGraph는 UReplicationGraphNodes들을 포함합니다. 이러한 노드는 각 Connection에 대해 복제할 액터 목록을 생성하는 역할을 합니다. 이러한 목록의 대부분은 프레임 간에 지속됩니다.(→ 하나의 프레임에서만 사용되지 않습니다) 이를 통해 대부분의 gathering work("복제를 위해 고려해야 할 액터들을 모으는 작업")을 공유/재사용할 수 있습니다. 노드는 Global(모든 Connection에서 사용됨), Connection specific(각 Connection마다 자체의 노드가 있음) 또는 Shared(예: 팀: 동일한 팀의 모든 Connection은 공유됨)일 수 있습니다. Actor는 여러 노드에 있을 수 있습니다! 예를 들어 Pawn은 Spatialization Node에 있을 수 있지만 AlwaysRelevant_ForTeam Node에도 있을 수 있습니다. 그럴 경우, 팀원에게는 두 번 return됩니다. 가능한 최소화해야 하지만 괜찮습니다.
[ Lyra Nodes ]
These are the top level nodes currently used:
현재 사용되는 최상위 노드는 다음과 같습니다.
- UReplicationGraphNode_GridSpatialization2D
This is the spatialization node. All "distance based relevant" actors will be routed here. This node divides the map into a 2D grid. Each cell in the grid contains children nodes that hold lists of actors based on how they update/go dormant. Actors are put in multiple cells. Connections pull from the single cell they are in.
이것은 Spatialization Node입니다. 모든 "distance에 관련된" 액터가 여기로 라우팅됩니다. 이 노드는 맵을 2D Grid로 나눕니다. Grid의 각 Cell에는 액터가 업데이트 방식/Dormant로 변경되는 방식에 따라 액터 목록을 보관하는 자식 노드가 있습니다. 액터는 여러 셀에 배치됩니다. Connection은 해당 액터가 있는 단일 셀에서 가져옵니다.
→ Static / Dynamic / Dormant
- UReplicationGraphNode_ActorList
This is an actor list node that contains the always relevant actors. These actors are always relevant to every connection.
이것은 항상 관련성(AlwaysRelevant) 있는 액터를 포함하는 액터 목록 노드입니다. 이러한 액터는 모든 Connection과 항상 관련이 있습니다.
(// : e.g. PlayerState, GameState)
- ULyraReplicationGraphNode_AlwaysRelevant_ForConnection
This is the node for connection specific always relevant actors. This node does not maintain a persistent list but builds it each frame. This is possible because (currently) these actors are all easily accessed from the PlayerController. A persistent list would require notifications to be broadcast when these actors change, which would be possible but currently not necessary.
이것은 Connection별로 항상 관련성(AlwaysRelevant_ForConnection) 있는 액터에 대한 노드입니다. 이 노드는 Persistent List(프레임간에 공유되는걸 뜻함)를 유지하지 않고 각 프레임마다 목록을 빌드합니다. 이는 (현재) 이러한 액터가 모두 PlayerController에서 쉽게 액세스할 수 있기 때문에 가능합니다. Persistent List는 이러한 액터가 변경될 때 알림을 브로드캐스트해야 하며, 이는 가능하지만 현재는 필요하지 않습니다.
- ULyraReplicationGraphNode_PlayerStateFrequencyLimiter
A custom node for handling player state replication. This replicates a small rolling set of player states (currently 2/frame). This is so player states replicate to simulated connections at a low, steady frequency, and to take advantage of serialization sharing. Auto proxy player states are replicated at higher frequency (to the owning connection only) via ULyraReplicationGraphNode_AlwaysRelevant_ForConnection.
PlayerState 복제를 처리하기 위한 커스텀 노드입니다. 이는 작은 롤링 PlayerState 집합(현재 2/frame)을 복제합니다. 이는 PlayerState가 낮고 안정적인 빈도로 Simulated Connection에 복제되고 직렬화 공유를 활용하기 위한 것입니다. Autonomous Proxy인 PlayerState는 ULyraReplicationGraphNode_AlwaysRelevant_ForConnection을 통해 더 높은 빈도로(Owning Connection에만) 복제됩니다.
- UReplicationGraphNode_TearOff_ForConnection
Connection specific node for handling tear off actors. This is created and managed in the base implementation of Replication Graph.
TearOff 액터를 처리하기 위한 Connection별 노드입니다. 이는 ReplicationGraph의 기본 구현에서 생성 및 관리됩니다.
→ 엔진단에서 기본적으로 수행.
[ Dependent Actors (ALyraWeapon) ]
Replication Graph introduces a concept of dependent actor replication. This is an actor (ALyraWeapon) that only replicates when another actor replicates (Pawn). I.e, the weapon actor itself never goes into the Replication Graph. It is never gathered on its own and never prioritized. It just has a chance to replicate when the Pawn replicates. This keeps the graph leaner since no extra work has to be done for the weapon actors.
ReplicationGraph는 DependentActor 복제 개념을 도입합니다. 이것은 다른 액터(Pawn)가 복제할 때만 복제하는 액터(ALyraWeapon)입니다. 즉, 무기 액터 자체는 복제 그래프에 절대 들어가지 않습니다. 스스로 gather(수집)되지 않고 prioritized되지 않습니다. Pawn이 복제할 때 복제할 기회만 있습니다. 이렇게 하면 무기 액터에 대해 추가 작업을 수행할 필요가 없으므로 그래프가 더 간소해집니다.
Something to note is how this parent/dependent relationship can affect certain functionality, such as ForceNetUpdate and dormancy. Unless the dependent is routed elsewhere in the graph, it will rely entirely on the parent to be replicated. This means that if ForceNetUpdate is called on only the dependent, it will have no effect, but calling ForceNetUpdate on the parent will force both actors to replicate on the next update. This also means if the parent is set as dormant, the dependent will no longer replicate despite not being marked as dormant itself, which can lead to the dependent actor's channel being closed due to inactivity.
주의해야 할 점은 이 부모/종속(parent/dependent) 관계가 ForceNetUpdate 및 Dormancy과 같은 특정 기능에 어떤 영향을 미칠 수 있는지입니다. 종속(Dependent) 액터가 그래프의 다른 곳으로 라우팅되지 않는 한 복제되기 위해 부모에 전적으로 의존합니다. 즉, ForceNetUpdate가 종속(Dependent) 액터에서만 호출된다면 효과가 없지만 부모에서 ForceNetUpdate를 호출하면 두 액터가 다음 업데이트에서 같이 복제되도록 강제합니다. 이는 또한 부모가 Dormant로 설정된 경우 종속(Dependent) 액터는 Dormant로 표시되지 않았음에도 더 이상 복제되지 않으며, 이로 인해 종속된(Dependent) 액터의 채널이 비활성으로 인해 닫힐 수 있습니다.
See ULyraReplicationGraph::OnCharacterWeaponChange: this is how actors are added/removed from the dependent actor list.
ULyraReplicationGraph::OnCharacterWeaponChange를 참고하세요. 이는 액터가 종속된(Dependent) 액터 목록에 추가/제거되는 방식입니다.
/* 라고 되어 있으나 Lyra에서는 Depedent Actor 관련 기능이 구현되어 있지 않다. ShooterGame을 봐야 한다. 아마도 ShooterGame의 주석을 그대로 옮겨다가 수정만 해놓은듯... 이걸 알아차렸는지 5.4에선 이 주석이 삭제되었다. */
[ How To Use ]
Making something always relevant: Please avoid if you can :) If you must, just setting AActor::bAlwaysRelevant = true in the class defaults will do it. Making something always relevant to connection: You will need to modify ULyraReplicationGraphNode_AlwaysRelevant_ForConnection::GatherActorListsForConnection.
You will also want to make sure the actor does not get put in one of the other nodes. The safest way to do this is by setting its EClassRepNodeMapping to NotRouted in ULyraReplicationGraph::InitGlobalActorClassSettings.
AlwaysRelevant한 것을 만들기: 가능하면 피하세요 :) 꼭 해야 한다면 CDO에서 AActor::bAlwaysRelevant = true로 설정하면 됩니다.
Connection에 AlwaysRelevant한 것을 만들기: ULyraReplicationGraphNode_AlwaysRelevant_ForConnection::GatherActorListsForConnection을 수정해야 합니다.
액터가 다른 노드들 중 하나에 배치되지 않도록 해야 합니다.
가장 안전한 방법은 ULyraReplicationGraph::InitGlobalActorClassSettings에서 Policy를 의미하는 EClassRepNodeMapping을 NotRouted로 설정하는 것입니다.
[ How To Debug ]
Its a good idea to just disable ReplicationGraph to see if your problem is specific to this system or just general replication/game play problem. If it is replication graph related, there are several useful commands that can be used: see ReplicationGraph_Debugging.cpp. The most useful are below. Use the 'cheat' command to run these on the server from a client.
문제가 이 시스템에만 국한되어 있는지 아니면 일반적인 복제/게임 플레이 문제인지 확인하려면 ReplicationGraph를 비활성화하는 것이 좋습니다. ReplicationGraph와 관련된 경우 사용할 수 있는 몇 가지 유용한 명령어가 있습니다.
ReplicationGraph_Debugging.cpp를 참조하세요. 가장 유용한 명령어는 아래와 같습니다. 'cheat' 명령을 사용하여 클라이언트에서 서버에서 이를 실행합니다.
- "Net.RepGraph.PrintGraph" - this will print the graph to the log: each node and actor.
각 노드와 액터에 대한 그래프를 로그에 인쇄합니다.
- "Net.RepGraph.PrintGraph class" - same as above but will group by class.
위와 동일하지만 클래스별로 그룹화합니다.
- "Net.RepGraph.PrintGraph nclass" - same as above but will group by native classes (hides blueprint noise)
와 동일하지만 네이티브 클래스별로 그룹화합니다(블루프린트 노이즈 숨김).- Net.RepGraph.PrintAll <Frames> <ConnectionIdx> <"Class"/"Nclass"> - will print the entire graph, the gathered actors, and how they were prioritized for a given connection for X amount of frames.
전체 그래프, gather(수집)된 액터, 주어진 Connection에 대한 Priority가 X 프레임 동안 어떻게 지정되었는지를 출력합니다.
- Net.RepGraph.PrintAllActorInfo <ActorMatchString> - will print the class, global, and connection replication info associated with an actor/class. If MatchString is empty will print everything. Call directly from client.
Actor/Class와 연관되어있는 Class, Global 및 Connection Replication Info를 인쇄합니다. MatchString 이 비어 있으면 모든 것을 인쇄합니다. 클라이언트에서 직접 호출합니다.
- Lyra.RepGraph.PrintRouting - will print the EClassRepNodeMapping for each class. That is, how a given actor class is routed (or not) in the Replication Graph.
각 클래스에 대한 EClassRepNodeMapping을 인쇄합니다. 즉, 주어진 액터 클래스가 리플리케이션 그래프에서 라우팅되는 방식(또는 그렇지 않은 방식)을 출력합니다.
[ Deep Dive : ULyraReplicationGraph And UReplicationGraph Source Code ]
[ 컨테이너 중심 설명 ]
기본적으로 ReplicationGraph에서 사용하는 ENum, TArray, TClassMap 등 Connection들을 분류하기 위해 각종 정보를 저장하는 데이터/자료구조를 여러가지 사용한다.
ReplicationGraph.h, LyraReplicationGraphTypes.h, LyraReplicationGraph.h 등 여러 군데에 흩어져 있고 종류가 많아 이에 대한 이해를 전제로 시작해야 한다.
- EClassRepNodeMapping
어디로 라우팅되어야 하는지 정보를 enum class로 분류.
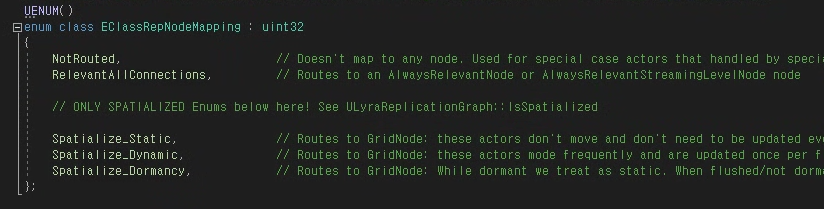
- TClassMap<EClassRepNodeMapping> ClassRepNodePolicies
{ UClass*, EClassRepNodeMapping }
UClass에 대응하는 EClassRepNodeMapping을 저장.
- FClassReplicationInfo (ReplicationGraphTypes.h)
Actor가 어떻게 복제될지에 대해 Class마다 저장하는 Actor Data.
DistancePriorityScale, StarvationPriorityScale, ReplicationPeriodFrame, CullDistanceSquared 등이 저장되어 있다.
InitClassReplicationInfo에서 인자로 들어와 CDO를 기반으로 NetCullDistanceSquared, ReplicationPeriodFrame을 채우는데, ConditionalInitClassReplicationInfo()로 래핑되어 있어 최종적으로 이 함수를 GlobalActorReplicationInfoMap에 들어갈 Class에 대한 FClassReplicationInfo를 채우기 위해 사용된다.

- TArray<UClass*> ExplicitlySetClasses (ULyraReplicationGraph)
ULyraReplicationGraph::InitGlobalActorClassSettings에서 명시적으로 설정된 UClass들을 보관하는 것.
Lyra를 기준으로 ACharacter, ALyraCharacter 2개의 클래스에 대해 명시적으로 정보를 추가해주고 있으며, 이 변수는 ConditionalInitClassReplicationInfo() 내에서 존재하는지 여부를 탐색하고 존재한다면 FClassReplicationInfo를 추가하지 않는 방식으로 사용된다.

- FGlobalActorReplicationInfoMap GlobalActorReplicationInfoMap
Replication Graph가 각 액터에 대해 전역적으로 보관하는 associative data입니다. 이 변수는 본질적으로 ReplicationGraph내에 위치하는데, 어디서나 쉽게 접근할 수 있게 하기위해 Constructor에서 FReplicationGraphGlobalData GraphGlobals에 주소를 저장해주고 있고, 이 GraphGlobals는 각 Node들이 생성될 때 CreateNewNode<>()내에서 InitNode() 함수를 통해 GraphGlobals를 들고 있게 합니다.
결국 ReplicationGraph뿐만 아니라 모든 Node들도 멤버 변수 GraphGlobals를 이용해서 GlobalActorReplicationInfoMap에 쉽게 접근할 수 있게 합니다.
-- ex. : Lyra --
앞선 항목들 중 FClassReplicationInfo, ExplicitlySetClasses는 최종적으로 이 변수를 세팅하기 위해 사용되는 것들이다. RegisterClassReplicationInfo()에서 추가되며, 이것을 포함한 현재까지의 모든 변수들과 함수들은 InitGloblActorClassSettings()라는 거대한 초기 세팅 함수내에서 전부 사용되는 것이다.

- RPC_Multicast_OpenChannelForClass
ReplicationGraph에서, 정확히는 ReplicationDriver에서 MulticastRPC가 작동하는 방식 또한 커스텀할 수 있다고 했다. 이런 부분까지 커스터마이징해줘야 하는데, 잘 생각해보면 기본값으로 들어가야하는 것들이 있을 것이다. 가령 MulticastRPC가 실행될 때, Controller에 대해서 ActorChannel을 열어줘야 할까? 절대 그래선 안될 것이다. 그렇기 때문에 이런 기본적인 설정하는 부분이 InitGlobalActorClassSettings() 내에서 존재한다.

Actor에 대해서는 열어주고, Controller에 대해서는 닫아버린다.

그 다음, 커스텀 설정된 것을 추가한다.
여기서는 ClassSettings에서 긁어와서 설정해주는데, ClassSettings는 UPROPERTY()에서 Config로 설정하게 되어 있어 Config 폴더의 DefaultGame.ini에서 텍스트로 하드코딩 되어 있다.
Lyra 기준으로 LyraPlayerController, PlayerState, LevelScriptActor, ReplicationGraphDebugActor가 추가되어 있으나, 위 코드에서 Channel을 열어주지 못하게끔 bAddToRPC_Multicast-OpenChannelForClassMap이 전부 False로 설정되어 있다.
- TClassMap<bool> ClassRebuildDenyList

어떤 Class가 Spatialization 내에서 Bias를 넘어갔을 때 Rebuild 할지 말지 목록을 가지고 있다.
InitGlobalGrapNodes() 내에서 AActor들은 전부 Rebuild를 하지않는 대상으로 추가한다.
Rebuild 되지 않으면 대신에 "Clamp" 된다.
Projectile의 경우 계속해서 날아가므로 Cell이 확장되는 Rebuild를 굳이 할 필요가 절대 없어 Clamp하는 것 같다.
/* : Rebuild가 무엇인지 알고 싶으면 UReplicationGraphNode_GridSpatialization2D::HandleActorOutOfSpatialBounds()와 UReplicationGraphNode_GridSpatialization2D::PrepareForReplication()의 "// Queued Rebuilds" 영역을 보세요.
1) 전자에선 ClassRebuildDenyList에 존재하지 않는다면 Rebuild를 위해 bNeedsRebuild를 true로 마킹하고, Bias를 넘어간 Actor의 Location을 기준으로 CellSize의 절반만큼 SpatialBias를 확장시킵니다.
2) 후자에선 bNeedsRebuild가 true로 마킹되어있다면 Cell들을 전부 삭제한 뒤, 확장된 SpatialBias를 기준으로 Cell들을 전부 새로 생성하고 Dynamic, Static Actor들을 재배치합니다. 이 때, Out Of Video Memory가 발생할 수 있어 Cell들을 MarkPendingKill한 뒤, 개수가 100개가 넘으면 GC를 강제로 돌려버립니다. */
- FActorRepListType (AActor*)

ReplicationGraph에서 AActor*를 FActorRepListType이라고 부른다.
/* Comment : 현재 복제 목록에 원시 AActor*를 사용하고 있습니다. 언젠가 이것을 ID나 배열 등에 빠르게 인덱싱할 수 있는 다른 것으로 바꾸고 싶을 수도 있습니다. (현재 연관 데이터에 해당하는 TMap을 사용하고 있으며, 정적 배열은 더 빠르지만 제약과 골치 아픈 문제가 있습니다.) 따라서 지금은 typedef와 일부 헬퍼 함수를 사용하여 FActorRepListType의 인터페이스/사용법을 호출합니다. */
- FActorRepListRefView
AActor*의 별칭인 FActorRepListType을 여러 개들고 있는 TArray.
TArray<FActorRepListType> RepList를 가지고 있는데, 쉽게 이해하기 위해서 복제될 TArray<AActor*>를 래핑해서 들고있다고 생각하면 된다.
한 마디로 "List of replicated Actors(복제되는 액터들의 목록)".
- TMap<FName, FActorRepListRefView> AlwaysRelevantStreamingLevelActors;
Level에 존재하는 Actor List를 저장하는 역할.
ULyraReplicationGraph::RouteAddNetworkActorToNodes()에서 새로운 Actor들이 들어올 때 마다, 정책이 RelevantAllConnections라면, AlwaysRelevant이므로 ActorInfo에 저장되어 있는 StreamingLevelName을 통해 TMap내에 존재하는지 확인하고, 없다면 새로만들어 추가한다.
그러니까 AlwaysRelevant Actor들이 각각 어느 Level에 존재하는지 관리하는 역할이다.
이는 나중에 GatherActorListsForConnection()내에서 새롭게 로드된 StreamingLevel이 있을 때 마다, 그 StreamingLevel에 해당하는 AlwaysRelevant Actor들을 찾아야하므로 이 컨테이너를 최종적으로 이용하게 되는 것이다.
[ 함수 호출 중심 설명 ]
- InitGlobalActorClassSettings()
/* ... */
- ULyraReplicationGraph::RouteAddNetworkActorToNoes()
- ULyraReplicationGraph::RouteRemoveNetworkActorToNodes()
ReplicationGraph에서 Actor가 Add/Remove 될 때 호출되는 함수.
그런데 이 함수는 결국 어디서 호출될까요?
RouteRemoveNetworkActorToNodes()의 경우 UReplicationGraph::RemoveNetworkActor()에서 호출되는데, ReplicationGraph는 결국 ReplicationDriver을 상속받은 Implementation이므로 ReplicationDriver->RemoveNetworkActor()의 호출을 추적하면 됩니다.
이 함수의 호출은 매우 많은 곳에서 호출되는데, 대표적인 AActor::Destroy() 내에서 호출순서는 이렇습니다.
AActor::Destroy()
- UWorld::DestroyActor()
-- UNetDriver::NotifyActorDestroyed()
--- UNetDriver::RemoveNetworkActor()
---- UReplicationDriver::RemoveNetworkActor()
RouteAddNetworkActorToNodes()도 비슷한데, ReplicationDriver()->AddNetworkActor()가 내부에서 호출되는 대표적인 함수는 아래와 같습니다.
- AActor::SpawnActor()
- SetReplicates()
- SetNetDormancy() (if (NewDormancy <= DORM_Awake))
- FlushNetDormancy()
- GatherActorListsForConnection(const FConnectionGatherActorListParameters& Params)
실제로 복제될 Actor List를 골라내는 핵심적인 함수. 모든 GraphNode에 존재함.
그런데 이 함수는 어디서 호출될까요?
이 함수는 인자로 넘어오는 FConnectionGatherActorListParameters& Params를 중심으로 이해해야 합니다.

우선 질문에 대한 답은 UReplicationGraph::ServerReplicateActors() 내에서 호출되는데, for loop를 통해 ConnectionGraphNodes를 순회할 때 Parameters를 넘기며 호출합니다.
그리고 각각의 GraphNode에 해당하는 가상함수인 GatherActorListsForConnection() 내에서, 참조로 넘어온 Params내에 포함된 OutGatheredReplicationLists의 정보를 커스텀 조건에 따라 채웁니다.

채워진 GatheredReplicationListsForConnection은 복제될 1차적인 목록이므로 ReplicateActorListsForConnections()를 통해 최종적인 복제 여부를 판정합니다.
- UReplicationGraph::ReplicateActorListsForConnections()
GatherActorListsForConnection()를 통해 결정된 1차적인 복제 목록은, 여기서 Priortized됩니다.
Actor가 ViewTarget, Viewer 인지, Starvation 되지는 않는지 등등 여러 Factor들을 종합해서 복제될 가능성을 판단짓는 AccumulatedPriority에 값을 더합니다. (대부분은 음수 값)
AccumulatedPriority 값을 기반으로 정렬하게되면, 우선순위에 따라 정렬되는 것이며 ReplicateActorsForReplication()내에서 ReplicateSingleActor()를 호출하며 내부에서 최종적인 복제여부를 판단하게 됩니다.
- ULyraReplicationGraph::InitConnectionGraphNodes(UNetReplicationGraphConnection*)
Connection마다 Init 하는 함수. Super에선 Tea-off Node를 생성해서 추가한다.
여기선 GraphNode 생성, StreamingLevel Load/Unload에 대한 델레게이트 바인딩을 하고, 최종적으로 인자로 들어온 RepGraphConnection(ConnectionManager라 보면 된다.) 에서 해당 노드를 추가해준다.
UReplicationGraph::CreateClientConnectionManagerInternal() 을 통해 호출되는데, 아래 순서로 호출된다.
( EOS, Steam 등 각 API의 NetDriver에서 InitBase를 호출하면서 시작 )
- UNetDriver::InitBase( /*...*/ )
-- UNetDriver::SetReplicationDriver( /*...*/ )
--- UReplicationDriver::InitForNetDriver( /*...*/ )
---- UReplicationGraph::AddClientConnection(UNetConnection*)
----- UReplicationGraph::CreateClientConnectionManagerInternal(UNetConnection*)
------ UReplicationGraph::InitConnectionGraphNodes(UNetReplicationGraphConnection*)

[ AddClientConnection() 호출 순서 ]
= IpNetDriver::ProcessConnectionlessPacket()
= USteamSocketsNetDriver::OnConnectionCreated()
-- NetDriver::AddClientConnection(UNetConnection* NewConnection)
--- ReplicationGraph::AddClientConnection(UNetConnection* NetConnection)
[ ProcessRemoteFunction() 호출 순서 ]
호출 시작점은 Actor외에도 ActorComponent, GameplayAbility 등이 있습니다.
Actor를 기준으로 정리하자면
- AActor::CallRemoteFunction()
-- UNetDriver::ProcessRemoteFunction()
--- ReplicationGraph::ProcessRemoteFunction()
[ GridSpatialization2D : 3 Spatialization Routing Policies - Static, Dynamic, Dormancy ]
1) AddActor_Static()
결코 움직일 수 없어 GridCell이 변경되지 않는 액터. 예를 들면 Wall, Tree
1-1) bWantsToBeDormant == true
최적화를 위해 Dormant 상태로 라우팅되어 들어왔나요?
GetDormancyNode()->AddDormantActor();
1-2) bWantsToBeDormant == false
깨어있는 Static Actor, 이제 StreamingLevelCollection 만이 관여하게 됨.
** AddActor_Static()으로 Routing된 경우, bNetDormancyDriven이 false로 들어오기 때문에 Dormancy Change와 관련한 Delegate는 GridCell에서 자체적으로 바인딩하게 됨. 반대로 true로 들어오는 경우는, 세번째 경우인 AddActor_Dormancy()
2) AddActor_Dynamic()
항상 자력으로 움직일 수 있어 GridCell을 자유롭게 넘나드는 액터. 예를 들면 Pawn, Projectile.
TMap<FActorRepListType, FCachedDynamicActorInfo> DynamicSpatializedActors에 단순히 추가된다.
3) AddActor_Dormancy()
스스로 움직일 수 없으나, 외부의 힘에 의해 움직일 수 있어 GridCell을 드물게 넘나드는 액터. 예를 들면 아이템.
이말은 즉, 상황에 따라 Static이 될 수도 있고, Dynamic이 될 수도 있으며, 별개로 때에 따라 최적화를 위해 Dormancy 상태로도 바뀔 수 있다는 뜻이다.
그래서 SetNetDormancy() 또는 DORM_Initial을 통해 Dormancy 상태 여부에 따라 델레게이트로 바인딩된 OnNetDormancyChange 함수를 통해 Dynamic과 Static 목록 사이를 왔다갔다 가능하다.
많이 헷갈릴 수 있는데, AddActor_Dormancy()로 라우팅된 액터는 결국 Dormancy List 같은 것이 있어서 여기에 추가되는 것이 아니다. Static과 Dynamic을 Dormancy가 변경됨에 따라 자유롭게 넘나들 수 있는 권한을 가진다고 생각하면 된다.
Dormancy 변경에 따른 목록간 이동이 궁금하다면 아래 [ GridSpatialization2D : DormancyChange ]를 보세요.
[ GridSpatialization2D : DormancyChange ]
- AActor::SetNetDormancy(ENetDormancy NewDormancy) ( if (bDormancyChanged == true) )
-- UNetDriver::NotifyActorDormancyChange()
--- UReplicationDriver::NotifyActorDormancyChange()
---- (FGlobalActorReplicationInfo*) ActorRepInfo->Events.Dormancy.Broadcast(Actor, *ActorRepInfo, CurrentDormancy, OldDormancyState)
===== UReplicationGraphNode_GridSpatialization2D::OnNetDormancyChange() (via AddActor_Dormancy())
===== UReplicationGraphNode_GridCell::OnStaticActorNetDormancyChange() (via RouteAddNetworkActorToNodes(), case EClassRepNodeMapping::Spatialize_Static)
[ GridSpatialization2D : PrepareForReplication ]
Dynamic Actor의 위치를 업데이트하고, 이에 따라 Add되거나 Remove되는 여러 Cell을 방향마다 찾아내고 해당 GridCell Node에 있는 DynamicNode에 Actor들을 Add하고 Remove함.
Dave 선생님이 말했던 GridSpatialization2D의 상자 예제에 대해 알 수 있는 곳.
액터 주변 CullDistance에 따라 액터를 얻을 수 있는 주변 Cell 정보를 얻는 과정을 보려면 UReplicationGraphNode_GridSpatialization2D::GetGridNodesForActor() 내에서 실행하는 GetGridNodesForActor(Actor, GetCellInfoForActor(Actor, ActorRepInfo.WorldLocation, ActorRepInfo.Settings.GetCullDistance()), OutNodes); 를 보세요. GetCellInfoForActor()를 통해 얻을 수 있는 Cell의 좌표 범위를 얻어내고, 그 좌표 범위를 통해 해당하는 GridCell Node를 TArray<UReplicationGraphNode_GridCell*>& OutNodes에 채워줍니다.
[ GridSpatialization2D : GatherActorListsForConnection ]
이전 Cell 위치와 현재 Cell 위치를 비교해서 변경된 Dynamic Dormant Actor를 업데이트하고 얻어낸 "Current Node Dormant list에 없는 Previous Dormant 액터들" 에 대해서 ConnectionDormancyNode로 하여금 NotifyActorDormancyFlush(Actor)를 호출합니다.
[ 매우 간단한 복제 흐름 - 이번 프레임이 복제되어야 하는 프레임인가요? (예외 : DynamicSpatialFrequency) ]
- ServerReplicateActors()
-- GatherActorListsForConnection() - (복제될 리스트 수집후 반환)
--- ReplicateActorListsForConnections_Default()
---- ReadyForNextReplication() - (이번 프레임이 복제될 프레임이 아니라면, Continue.)
----- Priortize Phase (Prioritize → Sort) (Saturation이 발생하기 전까지 우선적으로 복제할 리스트 선별)
------- ReplicateActorsForConnection()
-------- ReplicateSingleActor() - (실질적인 복제 진행, 마지막으로 복제된 프레임과 다음 복제될 프레임 기록)
--------- IsConnectionReady() - 이번 프레임에서 해당 Connection에 대한 Bandwidth 한도에 다다랐다면, break

아직 이 연결에서 복제할 시간이 아니라면 건너뜁니다. 여기서 ForceNetUpdateFrame을 살펴봐야 합니다. ForceNetUpdate가 호출될 때 모든 연결에서 NextReplicationFrameNum을 무효화(clear)할 수 있습니다. 하지만 이는 프레임당 전체적으로 더 많은 작업을 의미할 수 있습니다. 고려해야 할 사항입니다.
[ Unknown GraphNode added in 4.22 : UReplicationGraphNode_DynamicSpatialFrequency ]
==========================================================
[ Engine Code Comment ]
Notes on Default Zone Values
- Below values assume 30hz tick rate (the default UNetDriver::NetServerMaxTickRate value).
아래 값은 30hz 틱레이트(기본 UNetDriver::NetServerMaxTickRate 값)를 가정합니다.
- If you have a different tick rate, you should reinitialize this data structure yourself. See ReInitDynamicSpatializationSettingsCmd as an example of how to do this from a game project.
다른 틱레이트가 있는 경우 이 자료 구조를 직접 다시 초기화해야 합니다. 게임 프로젝트에서 이를 수행하는 방법의 예로
ReInitDynamicSpatializationSettingsCmd를 참고하세요.
- Alternatively, you can make your own subclass of UReplicationGraphNode_DynamicSpatialFrequency or set UReplicationGraphNode_DynamicSpatialFrequency::Settings*.
또는 UReplicationGraphNode_DynamicSpatialFrequency의 커스텀 서브클래스를 만들거나 UReplicationGraphNode_DynamicSpatialFrequency::Settings*를 설정할 수 있습니다
Overview of algorithm:
1. Determine which zone you are in based on DOT product
내적을 기준으로 어느 영역에 있는지 확인합니다.
2. Calculate % of distance/NetCullDistance
Dist/NetCullDistance의 %를 계산합니다.
3. Map+clamp calculated % to MinPCT/MaxPCT.
계산된 %를 MinPCT/MaxPCT에 매핑+클램핑합니다.
4. Take calculated % (between 0-1) and map to MinDistHz - MaxDistHz.
계산된 %(0-1 사이)를 가져와 MinDistHz - MaxDistHz에 매핑합니다.
==========================================================
[ UE4.22 Release Note : Networking ]
- This node recalculates replication frequency per connection, based on the connections view angle and position.
이 노드는 Connections' view angle 및 position을 기반으로 replication frequency per connection을 다시 계산합니다.
- This node is different in that it replicates actors directly in place, rather than returning a replication list for the generic prioritization/replication functions.
이 노드는 일반적인 prioritization/replication 함수에 대해 복제할 목록을 리턴하는 대신, 액터를 그 자리에서 직접 복제한다는 점에서 다릅니다.
- Actors replicated by this node use their own bandwidth limits.
이 노드에 의해 복제된 액터는 자체적인 대역폭 제한을 사용합니다.
- Supports normal replication and fast/shared replication.
일반 복제와 FastShared 복제를 지원합니다.
==========================================================
[ nashine's comment ]
UReplicationGraphNode_DynamicSpatialFrequency 이 GraphNode는 ActorListFrequencyBuckets와 매우 유사합니다. 동기화 성능을 최적화하는 목적을 달성하기 위해 동기화해야 하는 Actor의 수를 줄이는 동시에 동기화 효과를 보장하려고 합니다. Connection View Location를 사용하여 Distance Clipping을 계산한 다음, Dot Product를 기반으로 Actor와 Connection View Target 사이의 각도를 계산합니다. 각도와 거리를 기반으로 예측된 버킷(존)에서 동기화 주기를 계산합니다.
[ hakuya's comment ]
DynamicSpatialFrequency 의 아이디어는 인간의 시각 시스템이 다양한 방향과 Spatial Frequency에 민감하게 반응한다는 점에서 'direction-selective'이고 'spatial-frequency-selective이라는 사실에서 비롯되었습니다. 이 기능을 기반으로 시야 내의 여러 방향(기본적으로 정면/측면/후면)을 다른 Frequency로 간단히 업데이트하여 경험에 영향을 주지 않으면서 성능을 최적화할 수 있습니다.
구현은 상당히 복잡합니다. 주변 영역을 일반적인 방향에 따라 여러 Zone으로 나눈 다음 Viewer에서 어느 Zone에 있는지에 따라 액터의 다음 업데이트 시점을 결정해야 합니다. 업데이트 주기에 대한 약간의 작업이 필요하므로 단일 시간 동기화 오버헤드가 높은 오브젝트에 적합할 수 있습니다.
[ my comment ]
언리얼 네트워크를 사용해서 기존에 구현 불가능한 장르의 게임을 만들려고 할 때, 최적화할 수 있는 극한의 방식이라고 생각합니다. 카메라의 시야 방향에 따라 현재 보이지 않고, 보이더라도 주의 깊게 보지 않는 영역과 거리에 따라 멀리있는 액터들의 Frequency를 매 프레임마다 재계산해서 낮춥니다. 그리고 자체적인 LoadBalancing을 해서 특정 프레임에 과도하게 몰려서 리플리케이트하지 않도록 하여 CPU 부하를 낮춥니다. 액터의 Relevancy를 결정하는 작업의 오버헤드가 클 때도 사용하면 도움이 됩니다. 기존의 복제 과정과 달리 복제되는 프레임에 해당될 때만 Relevancy를 결정하는 것이 가능하기 때문입니다.
[ comment with DsReplicationGraph in Unreal Fest 2024 Seoul ]

클라이언트 Viewer의 방향과 거리에 따라서 상대적인 NetFrequency를 적용한 코드 예제입니다.
Viewer 뒤쪽에 있는 액터는 거리에 따라서 7~8 프레임 간격으로, 측면과 후면에 위치한 경우에는 각각 5~8 프레임, 3~8 프레임 간격으로 다른 NetFrequency를 적용한 코드입니다.
이 과정을 통해, 동기화에 크게 이슈가 생기지 않는 선에서 NetBroadcast의 성능을 향상시킬 수 있습니다.
==========================================================
[ Comments about Engine Code : UReplicationGraphNode_DynamicSpatialFrequency ]
[ Properties ]
[ FSettings ]
- static FSettings DefaultSettings
Default settings used by all instance
모든 인스턴스에 대한 통일된 settings
→ 그래서 static으로 선언.
- FSettings* Settings
Per instance override settings (optional)
인스턴스마다 설정가능. (선택 사항)
[ FSpatializationZone ]
기준 액터에 대해 복제될 액터들을 Dot product하고, 결과 Cos 값을 통해 배치된 Zone에 따라 유동적인 RepPeriod를 적용하는 정보를 담음.
[ FDynamicSpatialFrequency_SortedItem ]
단일 프레임에서 복제될 예정인 Item들을 모은 리스트.
[ Functions ]
[ DynamicSpatialFrequency::GatherActorListsForConnection() ]
실제 Gather하는 방식이 "MaxNearestActors"에 따라 2가지 갈래로 나뉜다.
이후 이 함수내에서 복제까지 진행된다.
[1] Two passes: filter list down to MaxNearestActors actors based on distance. Then calc freq and resort
Two passes: MaxNearestActors 만큼의 액터들을 거리에 따라 리스트를 전달합니다. 그런 다음 frequency를 계산하고 재정렬합니다.
[2] Single pass : RepList -> Sorted frequency list. No cap on max number of actors to replicate
Single pass : RepList -> 정렬된 frequency 목록. 복제할 액터 수에대한 제한은 없음.
bool DoFullGather에 따라 나뉘는데, 잠재적인 복제대상을 전부 복제하는 것이 가능하다면 [2]로 넘어가고 그렇지 않다면 [1]만 실행된다고 생각하면된다.
그걸 비교하기 위해 MaxNearestActors와 StreamingList들을 보고 누적 카운트된 PossibleNumActors를 사용한다.
(if (PossibleNumActors > MaxNearestActors))
[3] 복제 진행
[ int32 OpportunisticLoadBalanceQuota ]
This is how many "not every frame" actors we should replicate this frame. When assigning dynamic frequencies we also track who is due to rep this frame and next frame.
If this frame has more than the next frame expects, we will deffer half of those reps this frame. This will naturally tend to spread things out. It is not perfect, but low cost.
Note that when an actor is starved (missed a replication frame) they will not be counted for any of this.
이것은 우리가 이 프레임을 복제해야 하는 "every frame이 아닌" 액터의 개수입니다. dynamic frequenices를 할당할 때 우리는 또한 누가 "this frame"과 "next frame"을 복제할 예정인지 추적합니다. this frame이 next frame이 예상하는 것보다 더 많은 경우, 우리는 this frame에 할당된 복제 수의 절반 만큼을 미룹니다. 이것은 자연스럽게 복제 빈도를 분산시키는 경향이 있습니다. 완벽하지는 않지만, 비용은 낮습니다. 액터가 굶주릴 때(복제 프레임을 놓친 경우) 이 중 어떤 것에 대해서도 계산되지 않는다는 점에 유의하세요.
int32 OpportunisticLoadBalanceQuota = (NumExpectedReplicationsThisFrame - NumExpectedReplicationsNextFrame) >> 1;
for (const FDynamicSpatialFrequency_SortedItem& Item : SortedReplicationList)
{
/* ... */
if (CVar_RepGraph_DynamicSpatialFrequency_OpportunisticLoadBalance && OpportunisticLoadBalanceQuota > 0 && Item.FramesTillReplicate == 0 && !ReplicatesEveryFrame(ConnectionInfo, Item.EnableFastPath))
{
OpportunisticLoadBalanceQuota--;
continue;
}
/* ... */
}
/* 현재 프레임에 복제할 액터 수와 다음 프레임에 복제할 액터 수를 추적해서, 현재 프레임에 복제될 횟수가 다음 프레임보다 훨씬 많은 경우, 우선순위가 높은 순으로 일부를 다음 프레임에 미뤄 CPU 부하를 완화하는 방식.
그렇기 때문에 OpportunisticLoadBalanceQuota(기회주의적인 로드밸런스 할당량)이라고 칭하는 것 같습니다.
예를 들면, 현재 프레임에 복제될 액터의 수가 10개이고, 다음 프레임에 복제될 액터의 수가 4개라면 굳이 현재 프레임에 10개를 복제하지 않고 다음 프레임으로 적절히 넘겨서 7번씩 나눠서 복제하는 것이 서버의 CPU 부하를 완화 시킬 수 있겠죠.
그러므로 (10 - 4)의 절반인 3개의 액터는 다음 프레임에 복제되도록 SortedReplicationList의 앞부분부터 스킵합니다. */
/* 엔진 주석에서는 'we will deffer half of those reps this frame' 이라고 되어있는데, 아마도 defer의 오타같습니다. 실제로 ThisFrame과 NextFrame에 각각 할당된 복제 횟수 차이의 절반이 OpportunisticLoadBalanceQuota인데, 이 횟수만큼 SortedReplicationList의 for loop 앞부분을 continue로 스킵하고 있습니다.
이렇게 스킵한다면 복제 프레임을 건너뛰기 때문에 우선순위가 자연스레 증가하게되는데, SortedReplicationList의 앞부분이라면 스킵됐어도 다음 프레임에서 복제될 확률이 높기 때문에 (저번 프레임에 정렬됐을 때 우선순위가 가장 높았던 것들 이면서 건너 뛰었기 때문에 우선순위 더욱 증가하므로) 어느정도 이치에 맞습니다. */
[ GatherActors_DistanceOnly() ]
RepList를 순회하며 각 Actor들에 대해 Viewer들 중 해당 Actor로 부터 가장 가까운 거리를 구하고, TArray<FDynamicSpatialFrequency_SortedItem> SortedReplicationList에 FDynamicSpatialFrequency_SortedItem(Actor, ShortestDistanceToActorSq, &GlobalInfo)를 Emplace.
* : [1] 에서 호출됨.
[ GatherActors() ]
위 Distance Only가 수행하는 작업과 더불어 CalcFrequencyForActor() 까지 호출.
이걸 나눈 이유는 DistanceOnly는 FullGather가 아니므로 이후 SortedReplicationList.SetNum(MaxNearestActors, false); 을 통해 우선순위가 뒤쳐지는 SortedItem을 잘라버리기 때문.
그렇기 때문에 여기서는 SetNum()없이 CalcFrequencyForActor()까지 호출 함.
* : [2] 에서 호출됨.
[ CalcFrequencyForActor() ]
해당 Actor에 대해 Frequency를 계산하는 핵심적인 기능 수행.

/* 여기서 캐릭터의 화면 기준으로, Side또한 보이는 것 아닌가 생각할 수 있다. 이건 인간의 시각 특성을 이용한 트릭인데, 게임을 하는 유저는 기본적으로 화면의 일부, 즉 Front에 집중할 가능성이 매우 높다. Side를 보고 싶다면 가만히 있는채로 Side를 보는게 아니라 마우스를 통해 회전하는 경향이 있기 때문이다. 그렇다면 이 GraphNode를 이용하는 카메라 시스템은 Top-Down이나 FPS보단 TPS의 최적화를 위해 만들어진 노드라고 예상할 수 있다.
*/
// Find Zone
Fvector ConnectionViewDir : ViewDir (Viewer가 여러개인 경우 가장 가까운 Viewer의 ViewDir)
FVector DirToActor : Viewer로부터 Actor까지의 거리 크기를 갖는 벡터
float DistanceToActor : Actor까지의 거리 (not sq)
FVector NormDirToActor : Actor까지의 Normalized Dir, (DirToActor / DistanceToActor를 통해 얻음)
float DotP : NormDirToActor와 ConnectionViewDir의 Dot Product. 이 값을 기반으로 Zone 확인.
(Zone index)
0 : Rear : (90' ~ 180')
1 : Side : DOT의 값이 0.71f ~= Cos 45' 를 의미. (45' ~ 90')
2 : Front : (0' ~ 45')

float DistPct : CullDist에 대한 DistanceToActor의 비율.
그러니까 컬링되지 않고 복제되는 범위내에 존재하는 한, (0, 1]의 범위를 갖는 거리의 "비율"
float BiasDistPct : DistPct - ZoneInfo.MinDistPct
이걸 통해 앞쪽에 위치한 Actor일 수록 MinDistPct 값이 커지므로, DistPct의 영향력이 감소함.
float FinalPCT : 최종적으로 계산하는 것은 (DistPct - MinDistPct) / (MaxDistPct - MinDistPct)를 [0, 1]로 클램핑하는 것인데, 처음 코드를 보면 의도를 알기가 상당히 힘들다.
주석을 리마인드 해보자면,
Overview of algorithm:
1. Determine which zone you are in based on DOT product
내적을 기준으로 어느 영역에 있는지 확인합니다.
2. Calculate % of distance/NetCullDistance
Dist/NetCullDistance의 %를 계산합니다.
3. Map+clamp calculated % to MinPCT/MaxPCT.
계산된 %를 MinPCT/MaxPCT에 매핑+클램핑합니다.
4. Take calculated % (between 0-1) and map to MinDistHz - MaxDistHz.
계산된 %(0-1 사이)를 가져와 MinDistHz - MaxDistHz에 매핑합니다.
3번에 해당한다.
이후 4번에 해당하는 CalcDynamicReplicationPeriod() 내부에서 매핑된 %값으로 RepPeriod를 재계산.
재계산했다면 OutReplicationPeriodFrame, OutNextReplicationFrame으로 내보내서 ConnectionInfo의 ReplicationPeriodFrame, NextReplicationFrameNum을 각각 변경한다.
변경된 NextReplicationFrameNum에서 현재 FrameNum을 빼서 최종적으로 FramesTillReplicate를 계산하는데, 복제되기 까지 몇 프레임 남았는지를 의미한다.
FramesTillReplicate가 0인 경우, 이번 프레임이 복제될 차례이므로 NumExpectedReplicationsThisFrame을 증가
1인 경우, 다음 프레임에 복제될 차례이므로 NumExpectedReplicationsNextFrame을 증가.
해당 함수는 SortedReplicationList을 순회하며 매 번 호출되므로, 현재 프레임에 복제될 개수와 다음 프레임에 복제될 개수를 카운트한다. 이후 (이전에 봤던) 3)에서 OpportunisticLoadBalanceQuota 를 이용하여 앞부분을 스킵하며 복제 진행.
[ CalcFrequencyForActor() 요약 ]
카메라로부터, Viewtarget을 바라보는 vector와 다른 액터들간의 vector를 이용해서 DotProduct 진행. 결정된 [-1, 1]의 cos 값을 이용해서, 어느 Zone에 해당하는지 1차적으로 확정한다. 그리고 만약 cos값이 음수여서 REAR에 해당하는 Zone이라고 가정해보자. 5~8 프레임 간격으로 복제한다면, 이제 Dist/NetCullDistance 비율인 FinalPCT에 따라 멀수록 8프레임마다 복제하도록, 가까울수록 5프레임마다 복제하도록 [5, 8] 구간에 매핑하여 변경된 Frequency 확정. 변경된 Frequency를 확인해서 이번 프레임에서 복제되어야 한다면 FDynamicSpatialFrequency_SortedItem를 생성하고 추가. 이 과정에서 이번 프레임과 다음 프레임에 복제될 프레임을 추적하여 차이가 크다면 OpportunisticLoadBalanceQuota를 이용해 적절히 스킵.
[ FastShared Note ]
[ FastShared Article written by Alex.K ]
One of the features provided by the Replication Graph is the option to set a Fast Shared Replication Path for certain actors. The fast shared path is a way to create an actor’s serialization data once and reuse it to all connections that replicate this actor on the same frame. This article seeks to provide a basic example and overview of how to set up the fast shared path for an actor in a Replication Graph.
Replication Grpah에서 제공하는 기능 중 하나는 특정 액터에 대한 Fast Shared Replication Path를 설정하는 옵션입니다. Fast Shared Path는 액터의 Serialization 데이터를 한 번 생성하여 동일한 프레임에서 이 액터를 복제하는 모든 Connection에 재사용하는 방법입니다. 이 문서에서는 Replication Graph에서 액터에 대한 Fast Shared Path를 설정하는 방법에 대한 기본적인 예와 개요를 제공합니다.
While any actor can implement a fast shared path for replication, a common use is for replicating a pawn’s movement data. Instead of serializing and recompressing the movement data multiple times for each connection, the fast shared path can instead just serialize it once and append the pre-serialized bits directly into the packets.
모든 액터가 복제를 위한 Fast Replication Path를 구현할 수 있지만, 일반적으로 폰의 이동 데이터를 복제하는 데 사용됩니다. 각 연결에 대해 이동 데이터를 여러 번 직렬화하고 다시 압축하는 대신, Fast Shared Path는 한 번만 직렬화하고 미리 직렬화된 비트를 패킷에 직접 추가할 수 있습니다.
To create a FastShared path for a pawn’s movement data, the first step is to define a custom struct containing all the data needed for the movement update. This struct should define a custom NetSerialize function and support shared serialization (see NetSerialization.h for more info on custom struct serialization).
폰의 이동 데이터에 대한 Fast Shared Path를 만들려면 첫 번째 단계는 이동 업데이트에 필요한 모든 데이터를 포함하는 커스텀 구조체를 정의하는 것입니다. 이 구조체는 커스텀 NetSerialize 함수를 정의하고 Shared Serialization를 지원해야 합니다. (사용자 지정 구조체 직렬화에 대한 자세한 내용은 NetSerialization.h를 보세요)
The pawn using this struct can then implement a function that first fills the struct’s data before sending it as the parameter of an unreliable multicast RPC. This unreliable multicast RPC is how the Replication Graph will serialize and send the struct to all clients. One thing to note is that when the FastShared path is used, normal property replication is skipped, so on net updates where a Replication Graph node decides that the FastShared path should be used for an actor, the only properties clients will receive for that actor will be the parameters of this multicast RPC.
이 구조체를 사용하는 폰은 UnReliable Mutlicast RPC의 매개변수로 보내기 전에 구조체의 데이터를 먼저 채우는 함수를 구현할 수 있습니다. 이 UnReliable Mutlicast RPC는 Replication Graph가 구조체를 직렬화하고 모든 클라이언트에 보내는 방법입니다. 주의해야 할 한 가지 사항은 FastShared 경로가 사용될 때 일반 Property 복제가 건너뛰어지므로 Replication Graph Node가 액터에 FastShared Path를 사용해야 한다고 결정하는 Net Update에서 클라이언트가 해당 액터에 대해 수신하는 유일한 Property들은 이 멀티캐스트 RPC의 Parameter가 됩니다.
Next, the Replication Graph needs to set the function and function name for the fast shared path in the pawn’s replication info.
다음으로 복제 그래프는 폰의 복제 정보에서 빠른 공유 경로에 대한 함수와 함수 이름을 설정해야 합니다.
예를 들어:

Finally, the pawn should be routed into a replication list that sets the EActorRepListTypeFlags::FastShared flag. A common node that does this is UReplicationGraphNode_ActorListFrequencyBuckets (when its DefaultSettings.EnableFastPath is true).
마지막으로, 폰은 EActorRepListTypeFlags::FastShared 플래그를 설정하는 Replication List으로 라우팅되어야 합니다. 이를 수행하는 일반적인 Node는 UReplicationGraphNode_ActorListFrequencyBuckets(DefaultSettings.EnableFastPath가 true인 경우)입니다.
Again, using the FastShared path for replicating movement info is just a common use case. Depending on the needs of a project, any actor can implement its own struct and fast shared replication function, and any node can route actors into a fast shared list.
다시 말하지만, Movement Info를 복제하기 위해 FastShared Path를 사용하는 것은 일반적인 사용 사례일 뿐입니다. 프로젝트의 필요에 따라 모든 액터는 자체 구조체와 Fast Shared Replication 함수를 구현할 수 있으며 모든 Node는 액터를 Fast Shared List로 라우팅할 수 있습니다.
[ FastShared Path information in ReplicationGraph.cpp ]
- Bind FClassReplicationInfo::FastSharedReplicationFunc to a function. That function should call a NetMulticast, Unreliable RPC with some parameters.
- FClassReplicationInfo::FastSharedReplicationFunc를 함수에 바인딩합니다. 해당 함수는 일부 매개변수와 함께 NetMulticast, Unreliable RPC를 호출해야 합니다.
- Those parameters are your "fastshared" data. It should be a struct of shareable data (no UObject references of connection specific data).
- 해당 매개변수는 "fastshared" 데이터입니다. 공유 가능한 데이터의 구조체여야 합니다(연결별 데이터의 UObject 참조 없음).
- Return actors of this type in a list with the EActorRepListTypeFlags::FastShared flag.
- EActorRepListTypeFlags::FastShared 플래그가 있는 목록에서 이 유형의 액터를 반환합니다.
- UReplicationGraphNode_ActorListFrequencyBuckets can do this. See ::GatherActorListsForConnection.
- UReplicationGraphNode_ActorListFrequencyBuckets에서 이를 수행할 수 있습니다. ::GatherActorListsForConnection을 참조하세요.
- (You must opt in to this by setting UReplicationGraphNode_ActorListFrequencyBuckets::EnableFastPath=true)
- (UReplicationGraphNode_ActorListFrequencyBuckets::EnableFastPath=true로 설정하여 이를 선택해야 합니다.)
[ Etc. Note ]
[ Startup Settings ]
- DefaultEngine.ini
[/Script/OnlineSubsystemSteam.SteamNetDriver]
ReplicationDriverClassName="/Script/RepGraphExample.AliceReplicationGraph"
[/Script/OnlineSubsystemUtils.IpNetDriver]
ReplicationDriverClassName="/Script/RepGraphExample.AliceReplicationGraph"
이외에 Plugin → ReplicationGraph 체크 후 재시작, Build.cs → Private에 ReplicationGraph 추가
[ UNetReplicationGraphConnection ]
Connection Node(커넥션 노드 : 빨간색), 글로벌 노드들은 ReplicationGraph 본체가 들고 있으나, 커넥션 노드는 커넥션 객체가 들고 있음.
여기서 커넥션은 ReplicationGraph내에서 Connection을 관리하기위해 한번 래핑한 객체를 말함. 그게 ReplicationGraph.h에 있는 UNetReplicationGrpahConnection, 여기에 TObjectPtr<UNetConnection> NetConnection이 있음.
[ NetDriver::TMap<FNetworkGUID, TUniquePtr<FActorDestructionInfo>> DestroyedStartupOrDormantActors ]
Engine Comment : 서버는 이 Map에 조인 진행 중 클라이언트가 알아야 하는 파괴된 모든 액터, 즉 시작 액터에 대한 항목을 추가합니다. 또한 개별 UNetConnection은 시작 액터 외에도 휴면 및 최근 휴면 액터에 대한 FActorDestructionInfo를 추적해야 하며(연관된 채널이 없기 때문에), 이 Map은 해당 FActorDestructionInfo도 저장합니다.
/* ULyraReplicationGraph::RouteRemoveNetworkActorToNodes()에서 제거되는 ActorInfo의 Policy가 RelevantAllConnections인 경우, SetActorDestructionInfoToIgnoreDistanceCulling(ActorInfo.GetActor()); 를 호출하며 해당 AActor가 가진 NetGUID를 통해 이 Map에 접근하여 DestructionInfo를 얻고, bIgnoreDistanceCulling을 true로 바꿉니다. */
[ BasicReplicationGraph Approach : AddActor_Domancy ]
Routing 과정에서 Spatialization에 해당하는 경우, Dormancy로 우선 추가한 뒤(AddActor_Dormancy), ActorInfo의 bWantsToDormant == false라면 내부에서 Static으로 변경되어 추가되고, 그렇지 않으면 Dynamic 으로 변경되어 추가된다.
여기서 이후 Dormancy가 변경될 수 있기 때문에, (가만히 있는 아이템이 외부 영향으로 움직이는 경우) OnNetDormancyChange를 내부에서 바인딩해준다.
[ Approach about PendingConnections : bOnlyRelevantToOwner ] : WIP
어떤 Actor가 bOnlyRelevantToOwner인 경우, 막상 Owner의 NetConnection이 아직 없을 수도 있음.
[ Library ]
[ Youtube ]
1) https://www.youtube.com/watch?v=CDnNAAzgltw
2) https://www.youtube.com/watch?v=VusAHXoHF3Y
3) https://www.youtube.com/watch?v=7P11RwKfuEM
4) https://www.youtube.com/watch?v=-E-rga2DQA8
[ Example Code ]
1) https://github.com/DaedalicEntertainment/ue4-replication-graph
2) https://github.com/locus84/LocusReplicationGraph
3) https://github.com/MazyModz/UE4-DAReplicationGraphExample
4) https://github.com/KieranNewland/RepGraph
[ Article & Tech Blog ]
(KR)
- https://middlescoregirl.tistory.com/3
(EN)
- https://dawnarc.com/2019/09/ue4networking-in-advanced-replication-graph/
- https://www.programmersought.com/article/18954546917/
- https://www.kierannewland.co.uk/replication-graph-how-to-reduce-network-bandwidth-in-unreal/
(JPN)
- https://www.docswell.com/s/EpicGamesJapan/ZWX64K-UE4_CEDEC19_MultiPlayerGame#p204
- https://qiita.com/donbutsu17/items/71aa94d2aa539e96db40
(CN)
- https://bokjan.com/2022/10/unreal-replication-graph.htm
- https://hakuya.me/learning/unreal/Unreal%20Replication%20%E7%AF%87/
- https://nashnie.github.io/none/2019/08/05/UE-replication-graph.html
- https://blog.csdn.net/zzgyy123/article/details/104089516
'UE5 > Network' 카테고리의 다른 글
| [UE5] SetPawn() : OnPossess in Client (0) | 2024.09.28 |
|---|---|
| Conditional Property Replication에 관한 짧은 분석 (0) | 2024.09.15 |
| Multiplayer in UE : How to Understand Network Replication (0) | 2024.08.29 |
| [UE5] About HUD After Seamless Travel (1) | 2024.08.22 |
| [UE5] Replication - Push Model (0) | 2024.07.31 |