컴퓨터 네트워크 - 한양대학교 이석복 교수
http://www.kocw.net/home/cview.do?cid=6166c077e545b736
1. 컴퓨터 네트워크 기본 1
Network edge : connection-oriented service
TCP - Transmission Control Protocol
TCP service [RFC 793]
1) reliable, in-order byte-stream data transfer
- loss : acknowledgements and retransmissions
2) flow control
- sender won't overwhelm receiver
3) congestion control
- senders "slow down sending rate" when network congested
Network edge : connectionless service
UDP - User Datagram Protocol [RFC 768]
1) connectionless
2) unreliable data transfer
3) no flow control
4) no congestion control
App's using TCP :
- HTTP (Web), FTP (file transfer), Telnet (remote login), SMTP (email)
App's using UDP :
- streaming media, teleconferencing, DNS, Internet telephony
사용 기준
Reliable이 필요 ex) 유실되면 안되는 경우
→ TCP
Reliable이 필요하지 않음 ex) 일부가 유실되어도 상관없는 경우
→ UDP
컴퓨터 네트워크에서 나오는 대부분의 용어는 P로 끝나게 되는데, 프로토콜을 의미함
: 인터넷에서 통신하기 위한 규칙
Network Core
Circuit Switching
출발지에서 목적지가는 길을 미리 만들어 놓는 것
Packet Switching : Statistical Multiplexing
패킷 단위로 받아서 들어온 순서대로 전달해주는 것
Compare
Circuit Switching vs Packet Switching
10 users vs 35 users
Q) 어떤 이유로 Packet Switching이 선택되었는가
A) 인터넷 사용되는 패턴에 의하면, 사용자가 항상 네트워크를 사용하는 것은 아니므로 Packet Switching 사용시 더 많은 사용자를 수용할 수 있게 된다.
Four sources of packet delay
How do loss and delay occur?

1. nodal processing delay (노드 처리 딜레이)
- check bit errors
- determine output line
2. queueing delay
- time waiting at output link for transmission
- depends on congestion level of router
라우터에는 나가는 속도보다 들어오는 속도가 더 빠를 경우, 임시로 저장해두는 buffer(혹은, queue)라는 것을 둠.

3. Transmission delay
패킷 : 데이터의 집합 - 비트의 집합
전송이라는 것은 결국 첫번째 비트부터 마지막 비트까지 링크로 뿜어져 나가는 것인데, 이를 나가게 하기 위한 bandwidth가 부족할 경우 발생.
따라서, (L / R)
4. Propagation delay
다음 라우터까지 도달하는데 걸리는 시간
→ 물리적인 한계가 있으므로 줄이기 힘듦
★ 대부분의 패킷 로스는 queue에서 발생.
: 사용자가 갑자기 몰리는 경우
TCP를 사용하는 경우, 재전송 방법
- 재전송에 대한 기능을 Client 및 Server에다가 몰아두고, 나머지 라우터들은 dump core라고 해서 단순 노동(= 전송) 기능만 넣어놨음
2. 컴퓨터 네트워크 기본 2
Packet 기반 전송의 문제점
: 사용자가 한번에 몰리면, 문제가 발생
나가는 packet보다 들어오는 packet이 훨씬 많을 경우, queue라는 buffer에 packet이 쌓이면서 delay 발생
queue에 delay가 너무 발생할 경우 더 이상 담을 수 없게 되므로 초과된 packet들은 loss 발생


What transport service does an app need?
1) data integrity (데이터 무결성)
2) throughput (처리)
3) timing (타이밍 요구사향)
4) security (보안)
application 계층 프로토콜의 내부 구현은 어떤 transport 프로토콜을 사용하고 있는가?

여기서 봐야할 것은 가장 많이 사용되는 Web - HTTP는 TCP로 구현되어 있음
따라서 HTTP 메시지가 교환되기 이전에, Connection이 형성되어야 함
HTTP Connections
1) non-persistent HTTP
- at most one object sent over TCP connection
-- connection then closed
- downloading multiple objects required multiple connections
2) persistent HTTP
- multiple objects can be sent over single TCP connection between client, server
실제로는 Non-persistent HTTP보다 Persistent HTTP를 디폴트로 사용
3. 애플리케이션 계층 1

Socket
- application과 network 사이의 인터페이스
SOCK_STREAM
- TCP
- Reliable
- In-order guaranteed
- Connection-Oriented
- Bidirectional
SOCK_DGRAM
- UDP
- Unreliable
- No-order guarantees
- No notion of "connection" - app indicates dest. for each packet
- can send or receive
Multiplexing / demultiplexing
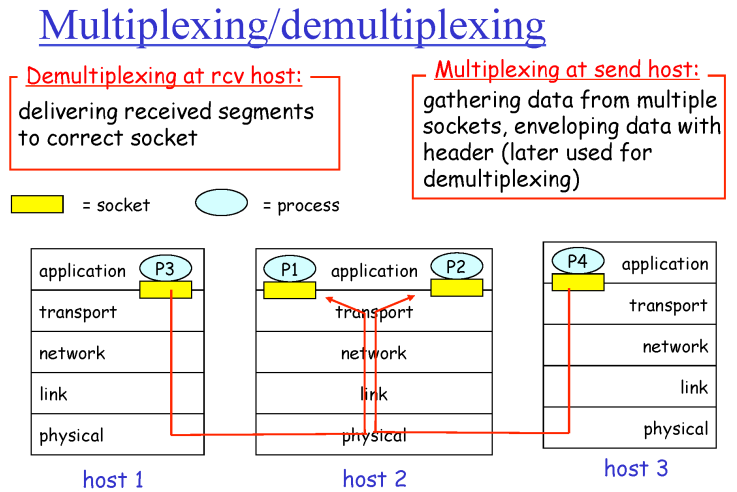

Segment는 Header와 Data로 이루어져 있다.
[
~ Connectionless Demux PPT (자료에 없음)
]
UDP

UDP, TCP, IP의 헤더 정보는 매우 중요
프로토콜의 동작 원리를 나타내기 때문에 어떤 필드들이 있는지에 대해 잘 알고 있어야 함.

UDP의 헤더 필드 개수는 4개
- source port
- dest port
- length
- checksum
4. 애플리케이션 계층 2
OSI 7계층 역할
- 각 Layer는 자기 자신의 상위 Layer에게 서비스를 제공해주고, 하위 Layer로부터 서비스를 제공받음
|App | |App |
|Transport| ---------------------------- Reliable --------------------> |Transport |
|Network | |Network |
|Link | |Link |
|Physical | |Physical |
Reliable은 Transport 계층에서 제공하는 것이므로, 하위 Layer는 본질적으로 Unreliable하다.
Unreliable하다는 것은 다음 2가지 경우가 발생한다는 것을 의미한다.
1) Packet Error
2) Packet Loss
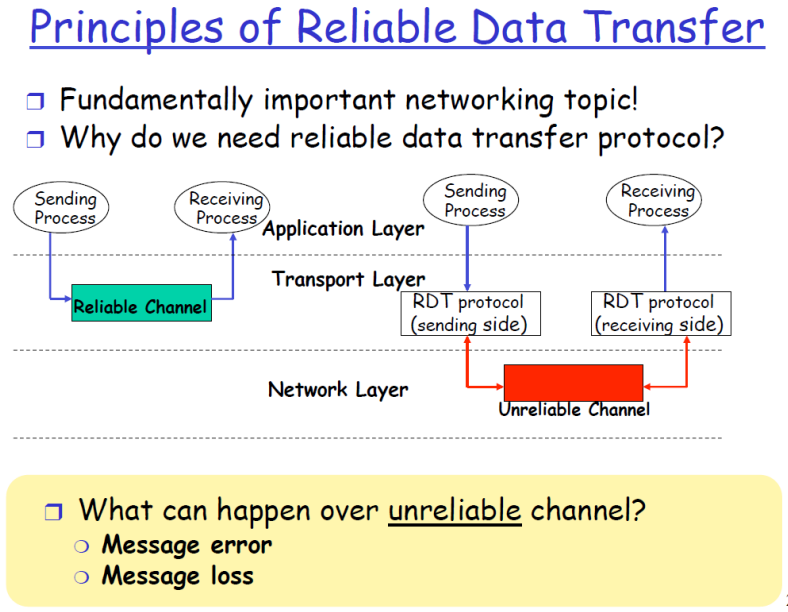
사고 실험
- Reliable Data Transfer Protocol을 디자인해보자.
-- 단순하게, 한 번에 1개씩의 패킷만 보낸다고 가정
Q) 에러없이 메시지를 받게 하려면 어떤 메커니즘이 필요할까?
1) Error Detection
일단, 패킷에 에러가 있는지 확인 필요
2) Feedback
잘받았는지 못받았는지 피드백 필요
- Acknowledgements (ACKs)
receiver explicitly tells sender that packet received correctly
- Negative acknowledgements (NAKs)
receiver explicitly tells sender that packet had errors
3) Retransmission
재전송
Q) 위 메커니즘으로 문제가 해결되었을까?
i) 첫번째 패킷에 대한 응답으로 ACK 또는 NAK를 받았다고 가정해보자. 해당 ACK, NAK에도 에러가 있을 수 있으므로 체크섬이 필요할 것이다. 그렇다면 만약 에러가 있다면 ACK, NAK 중 어느 것인지 파악이 가능할까? 불가능하다. 따라서, 해당 패킷은 의미가 없으므로 받지 않았다고 가정하고 재전송해야 한다.
ii) 그 다음, 재전송을 받은 receiver 입장에선 해당 패킷이 재전송된 패킷인지, 별도의 새로운 패킷인지 판단할 방법이 없으므로 이를 구별할 필요가 있다.
→ 패킷에 대한 번호(Sequence Number)를 부여한다, 재전송된 패킷은 동일한 번호(ex : 0, 0)를 가지므로 이를 구별가능해진다.
Q) Sequence Number에 대한 Field 크기를 최소화하고 싶다.
A) 1비트로 충분하다. 왜냐하면 동일한 번호를 받았으면 재전송된 패킷이고, 다른 번호를 받았다면 정상적으로 받은 패킷이기 떄문이다.
[ 위 내용 요약 ]

Q) NAK를 없앤 프로토콜도 가능할까?
A) ACK에 Sequnece Number를 포함시켜 전송하면 된다, Error Packet을 받았다면, Error Packet에 적힌 Sequence Number의 반대 번호(즉, 0이면 1, 1이면 0)로 ACK를 보내면 된다.

Sender는 "적당히" ACK를 기다리게 된다.
→ ACK를 기다리는 시간이 정해져 있지 않은 이유는, Trade-Off가 존재하기 때문, 대기 시간이 짧다면, 바로 재전송하면 되겠지만, 재전송 비용이 커질 것이다. 반대로 대기 시간이 길다면 늦게라도 패킷이 도달할 가능성이 있으므로 재전송 횟수는 적겠지만, 재전송에 대한 처리가 늦어질 것이다.
따라서, Network Overhead와 Packet Loss 극복에 대한 Trade-off 존재
Loss가 일어남으로써 가능한 4가지 시나리오


rdt 3.0은 Packet Error, Loss에 대한 기본적인 신뢰성을 보장하게 된다.
4가지 경우에 대해 시뮬레이션을 해보면서 복습해보자.

Error detection, Feedback, Retransmission, Sequence#은 전부 TCP Header의 Field로 구성되어있다. 게다가 Flow Control, Congestion Control 등까지 추가되어 있으므로 TCP Header의 크기는 클 수 밖에 없다.
여기서 알아본 RDT 프로토콜은 Reliable하긴 하지만, 너무 단순해서 성능적으로 형편없다.
실제로는 파이프라인 방식으로 한 번에 여러 개를 쏟아 보내고, 피드백을 다시 한 번에 받게 된다.

5. 전송 계층 1
Pipelined Protocol을 동작하게 만드는 기본적인 Approach 2가지를 다룰 예정
- Go-Back-N
- Selective Repeat
실제로 사용되진 않으나, 2가지 Approach
Utilization을 위해서, 많은 패킷들을 한 번에 쏟아 부을 것이다.
한꺼번에 얼마나 부을 것인가?
1. Go-Back-N
특정 패킷에 대한 Timer가 Ack를 받기전에 Time Out되면, Window내의 이후 패킷들을 재전송


→ pkt2에 대한 loss로 인해, 이후 pkt2 TimeOut이므로 paket2~5 재전송.
Window size가 엄청 크므로, 실제로는 사용되지 못함. 개념적인 이해가 필요
2. Selective Repeat
문제가 있을 때, 선택적으로 재전송
Time Out나기 전에, ACK를 받은 패킷은 재전송을 하지 않음.
→ Go-Back-N보다 조금 더 진화된 형태
유실난 패킷만 재전송하기 때문에 네트워크 부담이 적어지지만, Receiver가 해야할 일이 조금 추가될 수 있음.

Q) Window Size를 3개로 할 경우, 위 2개의 시나리오를 Receiver 입장에서 구분할 수 없다.
A) Window Size를 늘려서(Sequence Number도 같이 늘어나므로) 해결
다음 시간 예고
Q) 실제로는 Windw Size가 수백 수천개인데, 패킷마다 Timer를 달면 오버헤드가 엄청날 것이다.
A) 그래서 TCP에서는 Window당 대표하는 Timer 1개, ACK도 Go-Back-N처럼 cumulative Ack를 사용함
6. 전송 계층 2

1) pointer-to-point
- one sender, one receiver
2) reliable, in-order byte stream
- no "message boundaries"
3) pipelined
- TCP congestion and flow control set window size
4) full duplex data
- bi-directional data flow in same connection
5) connection-oriented
- handshaking (exchange of control msgs) init's sender, receiver state before data exchange
6) flow controlled
- sender will not overwhelm receiver

Port Number : 16비트이므로 하나의 PC에서 한 번에 최대 연결가능한 개수는 65535개.
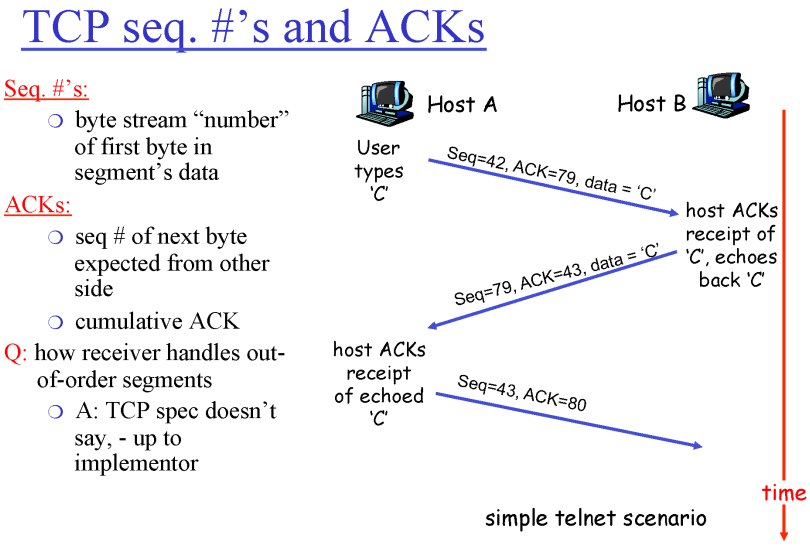
위는 Echo 서버
Seq=42, ACK=79, data = 'C'
- 42를 보내고 다음 수신으로 79를 기대한다는 의미 (C를 보냄)
Seq=79, ACK=43, data = 'C'
- 79를 보내고 다음 수신으로 43을 기대한다는 의미 (C를 Echo)
Seq=43, ACK=80
- 43을 보내고 다음 수신으로 80을 기대한다는 의미
FYI)
A, B가 Sender이면서 Receiver인 경우, 표준 TCP에서는 Ack를 보낼 때 500ms까지 기다렸다가 보내라고 권고한다. 500ms내에 송신할 패킷이 발생했다면 Ack를 보낼 때 같이 보내면 패킷 송신 횟수를 절약할 수 있기 때문이다.

Timeout에 대한 Trade-Off
- 대기시간이 짧을수록 반응시간이 좋아지지만, 패킷 재전송률이 늘어남
- 대기시간이 길수록 반응시간은 짧아지지만, 패킷 재전송률은 감소함
→ RTT값을 Timeout Value로 사용하고 싶다.
단, RTT를 측정해보면 동일한 라우터 경로를 따라더라도 네트워크 상황에 따라 매번 값이 다르게 나온다.
Queueing Delay등의 원인 존재
→ 특정 공식을 이용한 Estimed RTT값 사용

TCP는 Cummulative Ack
Optimization : Fast Retransmission
아무런 문제가 없다면 Ack 4, 5, 6, 7.. 이렇게 받을 것이다.
Ack10을 받고, 이후 같은 번호가 3DUP Ack를 받았을 때(총 4번), Timeout이 발생하기 전에 Packet Loss를 사전에 감지할 수 있다.
7. 전송 계층 3
TCP Flow Control


Receiver가 더 많이 받지 못하는 상황일 때, Sender가 초과해서 보내지 않도록 알려주는 것
Receive Buffer가 얼만큼 더 받을 수 있는지 알려주기 위해서,
TCP Header에는 "Receive Buffer Size"를 의미하는 Field가 존재한다.
- 내가 얼만큼 더 받을 수 있는지 알려주는 용도
→ Receive Window
Flow Control은 매우 중요한 개념이긴 하지만, 구현이 단순하기에 subchapter로 들어가 있음.
Receiver가 받을 수 있는 데이터가 없다고 해도, Sender는 비어있는 Data를 포함한 패킷을 지속적으로 보내게된다.
→ 이렇게 보내야 ACK를 다시 받아서 Receiver의 상황을 알 수 있기 때문(즉, Receive Buffer 상황 업데이트)
Q) Flow Control은 궁극적으로 보내는 양을 조절하는 것일까, 보내는 속도를 조절하는 것일까?
A) Recevie Buffer가 받을 수 있는 Size(Receive Window)가 클수록 mbps(bit/sec) 가 높아지는 것 이므로, 사실상 동일한 개념이다. 한 번에 많은 양을 보낼 수록 속도를 의미하는 mbps가 높아지기 때문
Situation)
Receiver가 ReceiveWindow를 0으로 해서 Ack를 보냈다고 하자. 더 이상 받을 수 없다는 의미이므로, Sender는 더 이상 보내지 않게 된다. 이후 Receiver가 받을 수 있는 Size가 100만큼 변경되었다고 하자.
Q) Sender는 마지막으로 받은 ReceiveWindow가 0인데 Receiver가 이제 다시 받을 수 있다는 것을 어떻게 알 수 있을까?
A) 알 수 없다. 따라서 Sender는 비어있는 Segment를 담은 패킷을 Receiver에게 보내서, ReceiveWindow가 담긴 Ack를 다시 받도록 주기적으로 시도해야 한다.
TCP 3-way Handshake
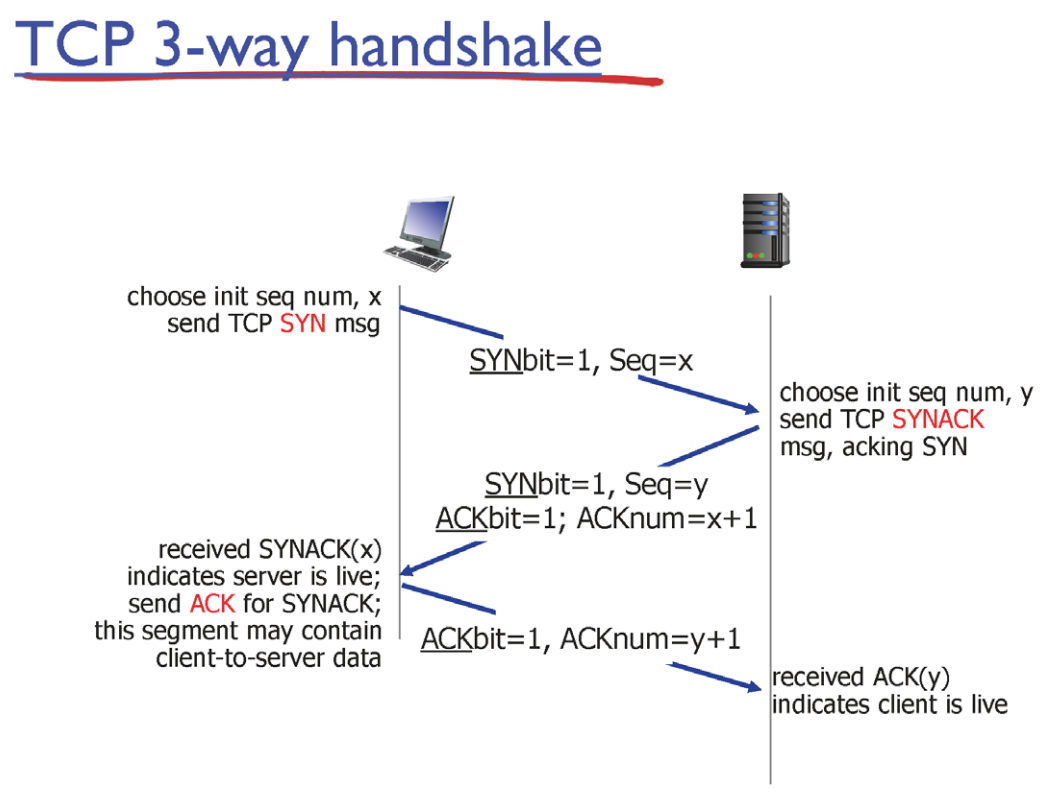
TCP Segment Header에, Sync라고 하는 1bit Field가 존재한다.
3-way Handshake가 진행될 때에 한해서만, 해당 Field가 true로 세팅된다. - Sync 즉, 연결하고 싶다는 의미
마지막 Ack는 Application Data를 포함할 수 있음.
Closing TCP Connection
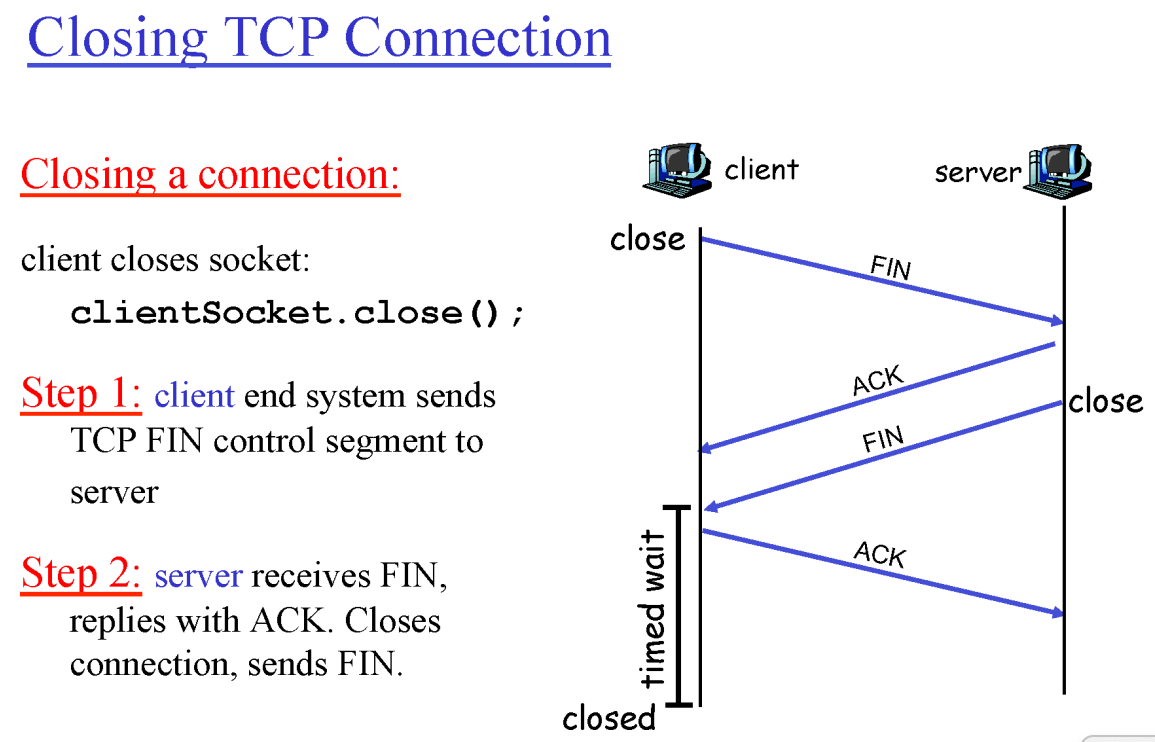
Client-Side에서 Timed Wait가 존재하는 이유
- Client가 마지막에 보낸 Ack가 유실되어 Server가 받지 못했을 경우, 서버가 FIN을 다시 보내게 되는데 해당 FIN에 대한 Ack를 클라이언트가 재전송하지 않고 Closed되어 버리는 만약의 경우를 대비하기 위해 일정 시간 동안 대기하는 것이다.
- Time-out Value는 고정된 값이 아니라, 유동적인 값을 가짐.
Approaches to TCP Congestion Control - Overview
Flow Control에서 다뤘던 recevWindow의 한계 값과, 네트워크 상황에 따른 한계 값 Net이 공존할 수 있다.
이 2개의 값 중, 더 낮은 값에 실제 전송량이 결정된다. (= min(Congestion Window, Receiver Window) )
Q) Receiver Window는, 실제 Receiver가 받을 수 있는 값을 적어서 Ack를 보내기 때문에 직접적으로 알 수 있다. 하지만, Congestion Window의 값은 어떻게 알 수 있을까?
A1) End-end congestion control
- no explicit feedback from network
- congestion inferred from end-system observed loss, delay
- approach taken by TCP
내부 상황을 추론해서 컨트롤
ACK가 느리게 오거나, 오지 않을 경우 문제가 생겼다고 추론.
A2) Network-assisted congestion control
- routers provide feedback to end systems
-- single bit indicating congestion (SNA, DECbit, TCP/IP ECN, ATM)
- explicit rate sender should send at
8. 전송 계층 4
TCP Congestion Control
3 main phases
1. Slow Start
- 1 MSS(Maximum Segment Size)부터 시작
2. Additive increase
- Packet Loss가 탐지될 때 까지, RTT마다 CongWin(Congestion Window)를 1씩 증가
- ACK를 받을 때 마다 1 MSS씩 증가 (1, 2, 4, 8, 16, ...)
- 즉, 초반에는 threshhold에 도달할 때 까지 exponential하게 빠르게 증가
3. Multiplicative decrease
- Packet Loss가 탐지되면, CongWin을 절반으로 감소
이를 sawtooth pattern(톱니 패턴)이라고도 함.
TCP Congestion Control : details
sender limits transmission
[ LastByteSent - LastByteAcked <= CongWin ]
Roughly,
rate = (CongWin / RTT ) - Bytes/sec
CongWin 값은 동적인데, 네트워크 혼잡 상황에 따라 결정됨.
Sender가 혼잡을 어떻게 감지하는가?
- loss event = timeout or 3 duplicate acks
- loss event가 발생하면, TCP sender는 rate를 감소시킴.
3개의 매커니즘
- Additive Increase, Multiplicative Decrease
- Slow Start
- Timeout 발생이후, 보수적으로 변경
TCP Tahoe vs TCP Reno

loss event = Timeout or 3 Duplicate Acks
TCP Tahoe
: Loss 발생시, Slow Start로 리셋. 즉, MSS(Maximum Segment Size) = 1
TCP Reno
: Loss 발생시, Threshhold를 절반으로 변경
3 Duplicate Acks
: 단일 패킷 로스
- CongWin, Threshold 사이즈를 모두 절반으로 낮추고, Linear Increase(= Additive Increase?) 시작
Timeout
: 심각한 에러
- Tahoe와 동일. 즉, Slow Start로 리셋 (MSS = 1)
FYI) Tahoe, Reno는 북캘리포니아에 있는 도시 이름. (TCP Vegas도 동일)
Q) Threshhold 값은 어떻게 정할 것인가?
A) 기본적으로 구현자의 몫이지만, 처음 Loss Event가 발생했을 때의 (MSS/2) 를 기준으로 잡는 것이 이상적.
또한, 다른 연결된 PC의 Threshhold 값을 가져와서 사용할 수도 있을 것임.
[ TCP Fairness ]

Fairness goal : K개의 TCP session들이 bandwidth R 만큼의 제한이 있을 때, 각각 고르게 써야할 것이므로 평균적으로 R/K만큼만 써야 한다.
Q) 이론적으로는 Fair해야 하지만, 실제로는 다르지 않을까?
A) 실제로, Fair 하게 된다.
Why is TCP fair?

2개의 경쟁 세션 존재한다고 가정.
위 표에서, 1번 Connection이 더 많은 bandwidth를 사용 중이라고 가정해보자.
어느 순간, Decrease가 발생할 경우, 1번 Connection 및 2번 Connection 전부 절반으로 감소하게된다.
→ 1번 Connection의 bandwidth 사용량이 더 많으므로, 감소된 양이 더 많게 된다.
즉, 상대적으로 2번 Connection의 사용량이 더 많아지게 된다. 따라서 1, 2 Connection의 사용량이 각각 Fair하게 수렴하게 된다.
Q) 결국 TCP끼리 Fair하게 되므로, 1번 Connection이 2개의 TCP를 사용할 경우 어떻게 될까?
A) 총 3개의 TCP가 열리므로 2번 Connection보다 1번 Connection의 bandwidth 사용량이 2배가 됨.
9. 네트워크 계층 1