https://youtu.be/5sZo3SrLrGA?si=BnFuL5phi4nNDfUN
(42:00~)
Hardware Reordering

you have a processor on the left edge here, and you have a network that connects it to the memory system, a memory bus of some kind.
여기 왼쪽 가장자리에 프로세서가 있고, 그것을 메모리 시스템에 연결하는 네트워크, 일종의 메모리 버스가 있습니다.

Now it turns out that the processor can issue stores faster than the network can handle them. So the processor can go store, store, store, store, store, store, but getting things into the memory system that can take a while. Memory system is big and it's slow.
But the hardware is usually not doing store on every cycle. It's doing some other things, so there are bubbles in that instruction stream. And so what it does is it says, well, I'm going to let you issue it because I don't want to hold you up. Ok?
So rather than being held up, let's just put them into a buffer, and so long as there's room in the buffer, I can issue them as fast as I need to. and then the memory system can suck them out of the buffer as it's going along. And so in critical places where there's a bunch of stores, it stores them in the buffer if the memory system can't handle. On average, of course, it's going to go at whatever the bottleneck is on the left or the right. You can't go faster than whichever is the bottleneck-- usually the memory system.
But we'd like to achieve that, and we don't want to have to stall every time we try to do two stores in a row, for example. By putting a little bit of a buffer, we can make it go faster.
이제 프로세서가 네트워크가 처리할 수 있는 것보다 더 빠르게 store 명령을 내릴 수 있다는 것이 밝혀졌습니다. 따라서 프로세서는 store, store, store, store, store를 할 수 있지만 메모리 시스템에 입력하는 데 시간이 걸릴 수 있습니다. 메모리 시스템은 크고 느리기때문이죠. 하지만 하드웨어는 일반적으로 모든 사이클에서 store를 수행하지 않습니다. 다른 작업을 수행하므로 해당 instruction stream에 버블(stall)이 있습니다. 그래서 하는 일은 "너를 지연시키고 싶지 않기 때문에 너가 명령을 내리도록 할게"라고 말하는 것입니다. 알겠어요? 지연되는 대신 버퍼에 저장하고 버퍼에 공간이 있는 한 필요한 만큼 빨리 명령내릴 수 있습니다. 그러면 메모리 시스템이 진행하면서 버퍼에서 항목을 빨아들일 수 있습니다. 따라서 많은 저장소가 있는 중요한 위치에서 메모리 시스템이 처리할 수 없는 경우 버퍼에 저장합니다. 물론 평균적으로 왼쪽이나 오른쪽에 있는 병목 현상에 도달할 것입니다. 병목 현상인 곳(보통 메모리 시스템)보다 더 빨리 갈 수는 없습니다. 하지만 우리는 그것을 이루고 싶고, 예를 들어 두 개의 store를 연속으로 하려고 할 때마다 멈추고 싶지 않습니다. 약간의 버퍼를 두면 더 빨리 갈 수 있습니다.

Now if I try to do a load, that can stall the processor until it's satisfied. So whenever you do a load, if there's no more instructions to execute it, if the next instruction to execute requires the value that's being loaded, the processor has to stall until it gets that value. So they don't want the loads to go thorugh the store buffer.
I mean, one solution would be just put everything into the store buffer. In some sense you'd be OK, but now I haven't covered over my load latency. So instead what they do is they do what's called a load bypass. They go directly to the memory system for the load bypassing all the writes that you've done up to that point and fetch it so that you get it to the memory system and the load bypass takes priority over the store buffer. But there's one problem with that hack, if you will. What's the problem with that hack? If I bypass the load, where could I run into trouble in terms of correctness?
If one your stores is the thing you're trying to load, Exactly.
이제 로드를 시도하면 프로세서가 만족할 때까지 멈출 수 있습니다. 따라서 로드를 수행할 때마다 실행할 명령어가 더 이상 없고 실행할 다음 명령어에 로드되는 값이 필요한 경우 프로세서는 해당 값을 얻을 때까지 멈춰야 합니다. 따라서 로드가 스토어 버퍼를 거치는 것을 원하지 않습니다. 한 가지 해결책은 모든 것을 스토어 버퍼에 넣는 것입니다. 어떤 의미에서는 괜찮을 수 있지만 로드 지연 시간은 다루지 않았습니다. 그래서 대신 로드 바이패스라고 하는 것을 합니다. 로드를 위해 메모리 시스템으로 직접 이동하여 그때까지 수행한 모든 쓰기를 바이패스하고 페치하여 메모리 시스템으로 가져오고 로드 바이패스가 스토어 버퍼보다 우선합니다. 하지만 이 hack에는 한 가지 문제가 있습니다. 이 hack의 문제점은 무엇일까요? 로드를 바이패스하면 정확성 측면에서 어디에서 문제가 생길 수 있을까요? 만약 여러분의 store 중 하나가 여러분이 load하려는 것일 때 문제가 생길 수 있습니다.
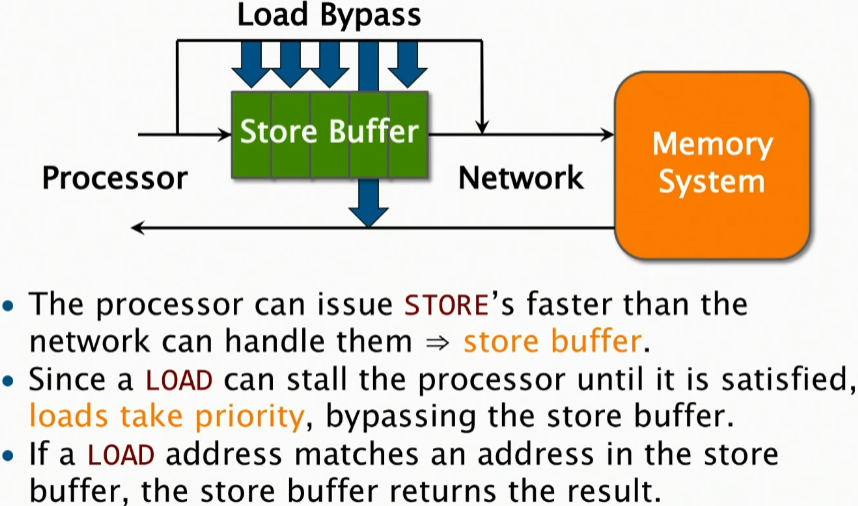
And so what happens is, as the load bypass is going by, it does an associative check in the hardware. Is the value that I'm fetching one of the values that is in the store buffer? And if so, it responds out of the store buffer directly rather than going into the memory system. Make Sense? so that's show the reordering happens within the machine.
그래서 일어나는 일은 로드 바이패스가 진행되면서 하드웨어에서 연관 검사를 하는 것입니다. 내가 가져오는 값이 스토어 버퍼에 있는 값 중 하나인가요? 그렇다면 메모리 시스템으로 들어가는 대신 스토어 버퍼에서 직접 응답합니다. 이해가 되시나요? 그래서 여기서 보여주는 것은 이 머신 내에서 발생한다는 겁니다.
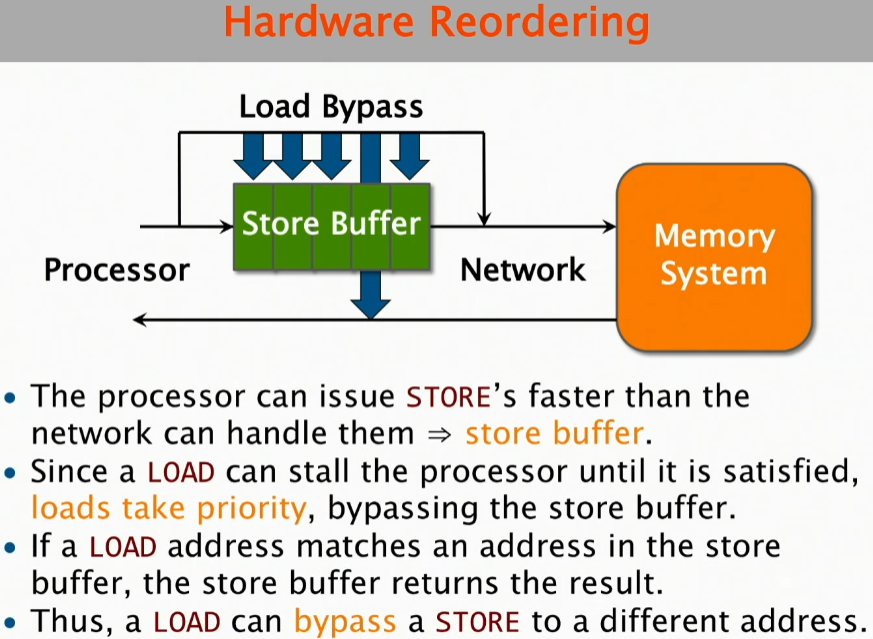
By this token, a load can bypass a store to a different address.
So this is how the hardware ends up reordering it, because the appearances is that the load occurred before the store occurred if you are looking at the memory from the point of view of the memory and in particular the point of view of another processor that's accessing that memory. So over here I said, you know Store, Load, over here it looks like he did, Load Store, OK? And so that's why it doesn't satisfy sequential consistency.
Q) So that store buffer would be one for for each processor?
A) Yeah, there's one for each processor. It's the way it gets things into the memory, right?
So I'll tell you, computing would be so easy if we didn't worry about performance. Because if those guys didn't worry about performance, they'd do the correct thing. They'd just put them in the right order. It's because we care about performance that we make our lives hard for ourselves. And then we have these kludges to fix them up.
So that's what's going on in the hardware, that's why things get reordered. Make Sense?
이 토큰에 따르면 로드는 스토어를 다른 주소로 우회할 수 있습니다. 그래서 하드웨어가 재정렬하는 방식인데, 메모리 관점에서, 특히 해당 메모리에 액세스하는 다른 프로세서의 관점에서 메모리를 보면 로드가 스토어보다 먼저 발생한 것처럼 보이기 때문입니다. 그래서 저는 여기서 스토어, 로드라고 말했고, 여기서는 로드 스토어라고 한 것처럼 보입니다. 알겠죠? 그래서 순차적 일관성을 충족하지 못하는 것입니다.
Q) 그러면 그 스토어 버퍼는 프로세서마다 하나씩인가요? A) 네, 프로세서마다 하나씩 있습니다. 메모리에 항목을 넣는 방식이죠, 맞죠? 그래서 말씀드리자면, 성능에 대해 걱정하지 않는다면 컴퓨팅이 정말 쉬울 겁니다. 왜냐하면 그 사람들이 성능에 대해 걱정하지 않는다면 올바른 일을 할 테니까요. 그냥 올바른 순서로 배치할 뿐이거든요. 우리가 성능에 신경 쓰기 때문에 우리 삶을 힘들게 만드는 거예요. 그리고 우리는 그것들을 고치기 위한 이런 엉터리 것들을 가지고 있습니다. 그래서 하드웨어에서 일어나는 일이고, 그래서 명령어들이 재정렬되는 것입니다. 이해하시나요?

But, it's not as if all bets are off. And in fact, x86 has a memory consistency model they call total store order.
here's the rules, so it's a weaker model.
하지만 모든 베팅이 취소된 것은 아닙니다. 사실, x86에는 total store order라고 하는 메모리 일관성 모델이 있습니다. 규칙은 다음과 같습니다. weaker model입니다.
And~ (47:18)
============ 정리 ============
Peterson's Algorithm
소프트웨어적으로 lock을 구현한 알고리즘.
이론상으로 완벽하지만, 현대 컴퓨터 아키텍쳐에선 Critical Section에 1개의 스레드만 진입하지 않는다.
왜냐하면 Cache, Pipeline에 의해 instruction reordering이 발생하기 때문.
이를 위해 memory fence(or, memory barrier) 를 사용.
mutex lock또한 내부적으로 memory fence가 사용됨.
썰 :
옛날에 인텔 CPU 어느 버전을 쓰는데 memory fence를 사용하는 mutex lock인데도 불구하고 memory fence가 mutex lock보다 성능이 비쌌던 적이 있었다.
확실한 원인은 모르지만, 내 이론에 의하면 주니어 엔지니어 데려다가 작업시켜놓고 방치해서 발생한 것 같다.
왼손이 한 일과 오른손이 한 일을 각자 알게해라...
기존 Peterson's Algorithm에서, memory fence을 사용하고 추가적으로 volatile 키워드를 붙여서 완성.
Implementing General Mutexes
1) Burns-Lynch Algorithm
LOAD와 STORE만으로 구현하려면 오메가(n) 공간이 필요
2) Attiya et al. Algorithm
memory fence 또는 atomic compare and swap같은 비싼 연산을 이용해서 구현
하드웨어 디자이너들이 특별한 명령어를 제공해야할 필요성 납득
(CAS)Compare-And-Swap
이게 왜 필요하죠?
mutex lock을 사용해서 동기화한다고 가정해보자.
unlock을 하기 직전에 time quantum이 만료되어 OS 스케줄러에 의해 context switching되었다면, 자물쇠를 들고 가버린 것.
다시 스케줄링될 때 까지 lock이 유지되는 상황이므로 엄청난 손실이 된다.
그래서 compare-and-swp을 이용하면 lock없이 동기화가 되는 것.
이 연산자체는 memory operation인데, 해당 메모리 주소의 값을 확인하고 바꿔치기 하는 것이다.
문제점으로는 ABA Problem이 있는데,
해당 메모리주소가 원래 A였는데 B로 바뀌었다가 다시 A로 바뀌고나서 확인했을 때 A였다면
A->B->A이므로 변화를 감지하지 못하는 문제가 있음.
해결하려면 CAS를 &&로 묶어서 연속으로 사용.
특별한 경우에 가끔 발생.
이런 명령어들은 매우 어렵고 사용하기 힘들기 때문에 많은 사람들이 알면 좋겠는데요.
역설적으로 이런걸 내부에 감춰두고 사람들이 몰라도 동기화할 수 있도록 하는게 중요합니다.